Off the Top: Knowledge Management Entries
Showing posts: 16-30 of 67 total posts
Getting Info into the Field with Extension
This week I was down in Raleigh, North Carolina to speak at National Extension Technology Conference (NETC) 2008, which is for the people running the web and technology components for what used to be the agricultural extension of state universities, but now includes much more. This was a great conference to connect with people trying to bring education, information, and knowledge services to all communities, including those in rural areas where only have dial-up connectivity to get internet access. The subject matter presented is very familiar to many other conferences I attend and present at, but with a slightly different twist, they focus on ease of use and access to information for everybody and not just the relatively early adopters. The real values of light easy to use interfaces that are clear to understand, well structured, easy to load, and include affordance in the initial design consideration is essential.
I sat in on a few sessions, so to help tie my presentation to the audience, but also listen to interest and problems as they compare to the organizations I normally talk to and work with (mid-size member organizations up to very large global enterprise). I sat in on a MOSS discussion. This discussion about Sharepoint was indiscernible from any other type of organization around getting it to work well, licensing, and really clumsy as well as restrictive sociality. The discussion about the templates for different types of interface (blogs and wikis) were the same as they they do not really do or act like the template names. The group seemed to have less frustration with the wiki template, although admitted it was far less than perfect, it did work to some degree with the blog template was a failure (I normally hear both are less than useful and only resemble the tools in name not use). [This still has me thinking Sharepoint is like the entry drug for social software in organizations, it looks and sounds right and cool, but is lacking the desired kick.]
I also sat down with the project leads and developers of an eXtension wide tool that is really interesting to me. It serves the eXtension community and they are really uncoupling the guts of the web tools to ease greater access to relevant information. This flattening of the structures and new ways of accessing information is already proving beneficial to them, but it also has brought up the potential to improve ease some of the transition for those new to the tools. I was able to provide feedback that should provide a good next step. I am looking forward to see that tool and the feedback in the next three to six months as it has incredible potential to ease information use into the hands that really need it. It will also be a good example for how other organizations can benefit from similar approaches.
Comments are open (with usual moderation) at this post at Getting Info into the Field with Extension :: Personal InfoCloud.
Explaining the Granular Social Network
This post on Granular Social Networks has been years in the making and is a follow-up to one I previously made in January 2005 on Granular Social Networks as a concept I had been presenting and talking about for quite some time at that point. In the past few years it has floated in and out of my presentations, but is quite often mentioned when the problems of much of the current social networking ideology comes up. Most of the social networking tools and services assume we are broadline friends with people we connect to, even when we are just "contacts" or other less than "friend" labels. The interest we have in others (and others in us) is rarely 100 percent and even rarer is that this 100 percent interest and appreciation is equal in both directions (I have yet to run across this in any pairing of people, but I am open to the option that it exists somewhere).
Social Tools Need to Embrace Granularity
What we have is partial likes in others and their interests and offerings. Our social tools have yet to grasp this and the few that do have only taken small steps to get there (I am rather impressed with Jaiku and their granular listening capability for their feed aggregation, which should be the starting point for all feed aggregators). Part of grasping the problem is a lack of quickly understanding the complexity, which leads to deconstructing and getting to two variables: 1) people (their identities online and their personas on various services) and 2) interests. These two elements and their combinations can (hopefully) be seen in the quick annotated video of one of my slides I have been using in presentations and workshops lately.
Showing Granular Social Network
Granular Social Network from Thomas Vander Wal on Vimeo.
The Granular Social Network begins with one person, lets take the self, and the various interest we have. In the example I am using just five elements of interest (work, music, movies, food, and biking). These are interest we have and share information about that we create or find. This sharing may be on one service or across many services and digital environments. The interests are taken as a whole as they make up our interests (most of us have more interests than five and we have various degrees of interest, but I am leaving that out for the sake of simplicity).
Connections with Others
Our digital social lives contain our interests, but as it is social it contains other people who are our contacts (friends is presumptive and gets in the way of understanding). These contacts have and share some interests in common with us. But, rarely do the share all of the same interest, let alone share the same perspective on these interests.
Mapping Interests with Contacts
But, we see when we map the interests across just six contacts that this lack of fully compatible interests makes things a wee bit more complicated than just a simple broadline friend. Even Facebook and their touted social graph does not come close to grasping this granularity as it is still a clumsy tool for sharing, finding, claiming, and capturing this granularity. If we think about trying a new service that we enjoy around music we can not easily group and capture then try to identify the people we are connected to on that new service from a service like Facebook, but using another service focussed on that interest area it could be a little easier.
When we start mapping our own interest back to the interest that other have quickly see that it is even more complicated. We may not have the same reciprocal interest in the same thing or same perception or context as the people we connect to. I illustrate with the first contact in yellow that we have interest in what they share about work or their interest in work, even though they are not stating or sharing that information publicly or even in selective social means. We may e-mail, chat in IM or talk face to face about work and would like to work with them in some manner. We want to follow what they share and share with them in a closer manner and that is what this visual relationship intends to mean. As we move across the connections we see that the reciprocal relationships are not always consistent. We do not always want to listen to all those who are sharing things, with use or the social collective in a service or even across services.
Focus On One Interest
Taking the complexity and noise out of the visualization the focus is placed on just music. We can easily see that there are four of our six contacts that have interest in music and are sharing their interest out. But, for various reasons we only have interests in what two of the four contacts share out. This relationship is not capturing what interest our contacts have in what we are sharing, it only captures what they share out.
Moving Social Connections Forward
Grasping this as a relatively simple representation of Granular Social Networks allows for us to begin to think about the social tools we are building. They need to start accounting for our granular interests. The Facebook groups as well as listserves and other group lists need to grasp the nature of individuals interests and provide the means to explicitly or implicitly start to understand and use these as filter options over time. When we are discussing portable social networks this understanding has be understood and the move toward embracing this understanding taken forward and enabled in the tools we build. The portable social network as well as social graph begin to have a really good value when the who is tied with what and why of interest. We are not there yet and I have rarely seen or heard these elements mentioned in the discussions.
One area of social tools where I see this value beginning to surface in through tagging for individuals to start to state (personally I see this as a private or closed declaration that only the person tagging see with the option of sharing with the person being tagged, or at least have this capability) the reasons for interest. But, when I look at tools like Last.fm I am not seeing this really taking off and I hear people talking about not fully understanding tagging as as it sometimes narrows the interest too narrowly. It is all an area for exploration and growth in understanding, but digital social tools, for them to have more value for following and filtering the flows in more manageable ways need to more in grasping this more granular understanding of social interaction between people in a digital space.
Social Tools for Mergers and Acquisitions
The announcement yesterday of Delta and Northwest airlines merging triggered a couple thoughts. One of the thoughts was sadness as I love the unusually wonderful customer service I get with Northwest, and loathe the now expected poor and often nasty treatment by Delta staff. Northwest does not have all the perks of in seat entertainment, but I will go with great customer service and bags that once in nearly 50 flights did not arrive with me.
But, there is a second thing. It is something that all mergers and large organization changes trigger...
Social Tools Are Great Aids for Change
Stewart Mader brought this to mind again in his post Onboarding: getting your new employees cleared for takeoff, which focusses on using wikis (he works for Atlassian and has been a strong proponent of wikis for years and has a great book on Wiki Patterns) as a means to share and update the information that is needed for transitions and the joining of two organizations.
I really like his write-up and have been pushing the social tools approach for a few years. The wiki is one means of gathering and sharing information. It is a good match with social bookmarking, which allows organizations that are coming together have their people find and tag things in their own context and perspective. This provides finding common objects that exist, but also sharing and learning what things are called from the different perspectives.
Communication Build Common Ground
Communication is a key cornerstone to any organization working with, merging with, or becoming a part of another. Communication needs common ground and social bookmarking that allows for all context and perspectives to be captured is essential to making this a success.
This is something I have presented on and provided advice in the past and really think and have seen that social tools are essentials in these times of transition. It is really rewarding when I see this working as I have been through organization mergers, going public, and major transitions in the days before these tools existed. I can not imaging thinking of transitioning with out these tools and service today. I have talked to many organizations after the fact that wished they had social bookmarking, blogs, and wikis to find and annotate items, provide the means to get messages out efficiently (e-mail is becoming a poor means of sharing valuable information), and working toward common understanding.
One large pain point in mergers and other transitions is the cultural change that brings new terms, new processes, new workflow, and disruption to patterns of understanding that became natural to the people in the organization. The ability to map what something was called and the way it was done to what it is now called and the new processes and flows is essential to success. This is exactly what the social tools provide. Social bookmarking is great for capturing terms, context, and perspectives and providing the ability to refind these new items using prior understanding with low cognitive costs. Blogs help communicate people's understanding as they are going through the process as well as explain the way forward. Wikis help map these individual elements that have been collectively provided and pull them together in one central understanding (while still pointing out to the various individual contributions to hold on to that context) in a collaborative (working together with one common goal) environment.
Increasing Speed and Lowering Cost of Transition
Another attribute of the social tools is the speed and cost at which the information is shared, identified, and aggregated. In the past the large consulting firms and the slow and expensive models for working were have been the common way forward for these times of change. Seeing social tools along with a few smart and nimble experts on solid deployments and social engagement will see similar results in days and a handful of weeks compared to many weeks and months of expensive change management plodding. The key is the people in the organizations know their concerns and needs, while providing them the tools to map their understanding and finding information and objects empowers the individuals while giving them knowledge and the means to share with others. This also helps the individuals grasp that are essential to the success and speed to the change. Most people resent being pushed and prodded into change and new environments, giving them the tools to understand and guide their own change management is incredibly helpful. This decreases the time for transition (for processes and emotionally) while also keeping the costs lower.
[Comments are open and moderated as always in the post at: Social Tools to Efficiently Build Common Ground :: Personal InfoCloud]
Denning and Yaholkovsky on Real Collaboration
The latest edition of the Communications of the ACM (Volume 51, Issue 4 - April 2008) includes an article on Getting to "we", which starts off by pointing out the misuse and mis-understanding of the term collaboration as well as the over use of the practice of collaboration when it is not proper for the need. The authors Peter Denning and Peter Yaholkovsky break down the tools needed for various knowledge needs into four categories: 1) Information sharing; 2) Coordination; 3) Cooperation; and Collaboration. The authors define collaboration as:
Collaboration generally means working together synergistically. If your work requires support and agreement of others before you can take action, you are collaborating.
The article continues on to point out that collaboration is often not the first choice of tools we should reach for, as gathering information, understanding, and working through options is really needed in order to get to the stages of agreement. Their article digs deeply into the resolving "messy problems" through proper collaboration methods. To note, the wiki - the usual darling of collaboration - is included in their "cooperation" examples and not Collaboration. Most of the tools many businesses consider in collaboration tools are in the lowest level, which is "information sharing". But, workflow managment falls into the coordination bucket.
This is one of the better breakdowns of tool sets I have seen. The groupings make a lot of sense and their framing of collaboration to take care of the messiest problems is rather good, but most of the tools and services that are considered to be collaborations tools do not even come close to that description or to the capabilities required.
[Comments are open at Denning and Yaholkovsky on Real Collaboration :: Personal InfoCloud]
Understanding Collective and Collaborative
I have finally blogged about the different between the two terms of collaborative and collective, which has been something bugging me for some time. Comments there are open, but are moderated (as they always have been). Those who have been to any of my workshops in the past year or so will see familiar information. Hopefully, the post will help those discussing and crafting social tools for the general web (or mobile) or large organizations will read and work to grasp the difference. I have had plenty of academics, researchers, and service developers push me to make this public for far too long so to start getting the misunderstanding around the two terms corrected.
Challenges as Opportunities for Social Networks and Services
Jeremiah Owyang posts "The Many Challenges of Social Network Sites" that lays out many of the complaints that have risen around social networking sites (and other social computing services). He has a good list of complaints, which all sounded incredibly familiar from the glory days of 1990 to 1992 for IT in the enterprise (tongue firmly planted in cheek). We have been through these similar cycles before, but things are much more connected now, but things also have changed very little (other than many of the faces). His question really needs addressing when dealing with Enterprise 2.0 efforts as these are the things I hear initially when talking with organizations too. Jeremiah asked for responses and the following is what I posted...
Response to Challenges of Social Network/Services
The past year or two, largely with Facebook growing the social networks and social computing tools have grown into the edges of mainstream. Nearly every argument made against these tools and services was laid down against e-mail, rich UI desktops (people spent hours changing the colors and arranging the interfaces), and IM years ago.
Where these tools are "seemingly" not working is mostly attributed to a severe lack of defining the value derived from using the tools. These news tools and services, even more so those of us working around them, need to communicate how to use the tools effectively and efficiently (efficiently is difficult as the many of the tools are difficult to use or the task flows are not as simple as they should be). The conceptual models & frameworks for those of us analyzing the tools have been really poor and missing giant perspectives and frameworks.
One of the biggest problems with many of these tools and services is they have yet to move out of early product mode. The tools and services are working on maturity getting features in the tools that people need and want, working on scaling, and iterating based on early adopters (the first two or three waves of people), which is not necessarily how those who follow will use the tools or need the tools to work.
Simplicity and limited options on top of tools that work easily and provide good derived value for the worklife and . As the tools that were disrupters to work culture in the past learned the focus needs to be on what is getting done and let people do it. Friending people, adding applications, tweaking the interface, etc. are not things that lead to easy monetization. Tools that help people really be social, interact, and get more value in their life (fun, entertainment, connecting with people near in thought, filtering information from the massive flow, and using the information and social connections in context where people need it) from the tools is there things must head. We are building the platforms for this, but we need to also focus on how to improve use of these platforms and have strong vision of what this is and how to get there.
[This is also posted at Challenges as Oppotunities for Social Networks and Services :: Personal InfoCloud with moderated comments turned on.]
Getting More Value In Enterprise with Social Bookmarking
The last few weeks I have been running across a few companies postponing or canceling their social computing or Enterprise 2.0 efforts. The reasons vary from the usual budget shifts and staff changes (prior projects were not delivered on time), and leadership roles need filling. But two firms had new concerns of layoffs or budget cuts.
To both firms I pointed out now was the exact time they really needed to focus on some Enterprise 2.0 efforts, particularly social bookmarking as well as wikis and blogs. These solutions help gather information, find value across the organization, capture knowledge, build cohesiveness for members of the organization in time where there there is uncertainty. One of the biggest reasons that these tools make sense is their cost to deploy and receive solid value. As Josh Bernoff (and others in from Forrester) points out in the Strategies For Interactive Marketing In A Recession free report from Forrester, the cost to deploy is in the $50,000 to $300,000 range (usually more expensive for large and more complex deployments).
Social Bookmarking has Great Value in the Enterprise
Every organization needs to know itself better then they currently do. The employees and members of the organization are all trying to do their job better and smarter. The need to connect people inside an organization with others with similar interest, contexts, and perceptions is really needed. I am a huge fan of social bookmarking tools to help along these lines as it helps people hold on to information they have need, want, or have interest in (particularly with future uses) and put things in their own context and perception. Once people understand the value they derive from using the tools to hold on to information out of their vast flow and streams of information and data that run before them each day they quickly "get it". As people also share these bookmarks in the organization with their tags and annotations, they also realize quickly they are becoming a valuable conduit to helping others find information and they grasp the value they will derive from being a resource that adds value in the organization. Other people derive value from information in the organization and outside it being augmented with individual perspectives and context. When this is pair with search, as Connectbeam does with their social search that pairs with existing FAST, Google Search Appliance, and others in-house search engines, the value the whole organization receives is far beyond the cost and minimal effort people are putting into the tools to get smarter, by more easily holding on and sharing what they know.
Nearly every attendee to the workshops I have put on around this subject quickly realizes they undervalued the impact and capability of social bookmarking (as well as other social computing tools) in the enterprise. The also provides a strong foundation for better understanding social computing to increase the derived value for all parties (individuals, collective users, collaborative users, and the organization).
Is is time for your enterprise to get smarter and provide more value inside and out?
[This is also blogged at Getting More Value In Enterprise with Social Bookmarking :: Personal InfoCloud with moderated comments turned on.]
Posting Elements of the Social Software Stack
I have been working for quite on finding a good way to explain the elements in the social software stack (or most of the important ones). I have blogged the result of the work as The Elements in the Social Software Stack (comments are open there).
In my public and in-house workshops I have worked through various graphics from others and my own to work as a foundation for talking to and through the subject. In November I finally sat down (in a hallway open space) the day before my workshop at the IA Konferenz in Stuttgart, Germany. It had all the elements that are part of a solid foundation, in progressive order:
- Identity
- Object (social object)
- Presence
- Actions
- Sharing
- Reputation
- Relationships
- Conversation
- Groups
- Collaboration
This and one other post that is in the works are becoming the corner stones for my work helping start-ups and enterprise work through social software (social computing) to properly solve their problems and address the issues at hand. It has also been the foundation for rethinking (mostly more clearly thinking about) social bookmarking and folksonomy. I am rewriting the work I have done toward the book based on these two pieces as it is making the communication of concepts clearer.
Who Does This Help?
People looking at the social software services should have a solid idea of the central elements, identity and the social object. After that it is a building process to account for the other elements leading up to the services full offerings. Social bookmarking (folksonomy related services) should get up to or include conversation. Tools like Ma.gnolia go up to groups for their social bookmarking service and they cover the elements leading up to that end point.
There is more that can be fleshed out in this, but it is a foundation and a starting point. The next piece will build on this posting and should be a good foundation for understanding.
Still here? Go read The Elements in the Social Software Stack :: Personal InfoCloud and offer constructive feedback. Thank you.
Can Facebook Change Its DNA
I wrote and posted Can Facebook Change Its DNA as a follow-up to for Business or LinkedIn Gets More Valuable regarding the changes needed in Facebook if it wants to be valuable (or have optimal value) for the business world.
A Stale State of Tagging?
David Weinberger posted a comment about Tagging like it was 2002, which quotes Matt Mower discussing the state of tagging. I mostly agree, but not completely. In the consumer space thing have been stagnant for a while, but in the enterprise space there is some good forward movement and some innovation taking place. But, let me break down a bit of what has gone on in the consumer space.
History of Tagging
The history of tagging in the consumer space is a much deeper and older topic than most have thought. One of the first consumer products to include tagging or annotations was the Lotus Magellan product, which appeared in 1988 and allowed annotations of documents and objects on one's hard drive to ease finding and refinding the them (it was a full text search which was remarkably fast for its day). By the mid-90s Compuserve had tagging for objects uploaded into its forum libraries. In 2001 Bitzi allowed tagging of any media what had a URL.
The down side of this tagging was the it did not capture identity and assuming every person uses words (tag terms) in the same manner is a quick trip to the tag dump where tags are not fully useful. In 2003 Joshua Schacter showed the way with del.icio.us that not only allowed identity, upon which we can disambiguate, but it also had a set object in common with all those identities tagging it. The common object being annotated allows for a beginning point to discern similarity of identityĵs tag terms. Part of this has been driven on Joshua's focus on the person consuming the content and allowing a means for that consumer to get back to their information and objects of interest. (It is around this concept that folksonomy was coined to separate it from the content publisher tagging and non-identity related tagging.) This picked up on the tagging for one's self that was in Lotus Magellan and brings it forward to the web.
Valuable Tagging
It was in del.icio.us that we saw tagging that really did not work well in the past begin to become valuable as the clarity in tag terms that was missing in most all other tagging systems was corrected for in the use of a common object being tagged and the identity of the tagger. This set the foundation for some great things to happen, but have great things happened?
Tagging Future Promise
Del.icio.us set many of out minds a flutter with insight into the dreams of the capability of tagging having a good foothold with proper structure under them. A brilliant next step was made by RawSugar (now gone) to use this structure to make ease of disambiguating the tag terms (by appleseed did you mean: Johnny Appleseed, appleseeds for gardening/farming, the appleseed in the fruit apple, or appleseed the anime movie?). RawSugar was a wee bit before its time as it is a tool that is needed after there tagging (particularly folksonomy related tagging systems) start scaling. It is a tool that many in enterprise are beginning to seek to help find clarity and greater value in their internal tagging systems they built 12 to 18 months ago or longer. Unfortunately, the venture capitalists did not have the vision that the creators of RawSugar did nor the patience needed for the market to catch-up to the need in a more mature market and they pulled the plug on the development of RawSugar to put the technology to use for another purpose (ironically as the market they needed was just easing into maturity).
The del.icio.us movement drove blog tags, laid out by Technorati. This mirrored the previous methods of publisher tagging, which is most often better served from set categories that usually are derived from a taxonomy or simple set (small or large) of controlled vocabulary terms. Part of the problem inherent in publisher tags and categories is that they are difficult to use outside of their own domain (however wide their domain is intended - a specific site or cross-sites of a publisher). Using tags from one blog to another blog has problems for the same reason that Bitzi and all other publisher tags have and had problems, they are missing identity of the tagger AND a clear common object being tagged. Publisher tags can work well as categories for aggregating similar content within a site or set of commonly published sites where a tag definition has been set (but that really makes them set categories) and used consistently. Using Technorati tag search most often surfaces this problem quickly with many variation of tag use surfacing or tag terms being used to attract traffic for non-related content (Technorati's keyword search is less problematic as it relies on the terms being used in context in the content - unfortunately the two searches have been tied together making search really messy at the moment). There is need for an improved tool that could take the blog tags and marry them to the linked items in the content (if that is what is being talked about - discerning predicate in blog tags is not clear yet).
Current Tools that Advanced
As of a year ago there were more than 140 social bookmarking tools in the consumer space, but there was little advancement. But, there are a few services that have innovated and brought new and valuable features to market in tagging. As mentioned recently Ma.gnolia has done a really good job of taking the next steps with social interaction in social bookmarking. Clipmarks pioneered the sub-page tagging and annotation in the consumer tagging space and has a really valuable resource in that tool. ConnectBeam is doing some really good things in the enterprise space, mostly taking the next couple steps that Yahoo MyWeb2 should have taken and pairing it with enterprise search. Sadly, del.icio.us (according to comments in their discussion board) is under a slow rebuilding of the underlying framework (but many complaints from enterprise companies I have worked with and spoken indepth with complain del.icio.us continually blocks their access and they prefer not to use the service and are finding current solutions and options to be better for them).
A Long Way to Go
While there are examples that tagging services have moved forward, there is so much more room to advance and improve. As people's own collection of tagged pages and objects have grown the tools are needed to better refind them. This will require time search and time related viewing/scanning of items. The ability to use co-occurance of tag terms (what other tags were used on the object), with useful interfaces to view and scan the possibilities.
Portability and interoperability is extremely important for both the individual person and enterprise to aggregate, migrate, and search across their collections across services and devices (now that devices have tagging and have had for some time, as in Mac OS X Tiger and now Vista). Enterprises should also have the ability to move external tagged items in through their firewall and publish out as needed, mostly on an employee level. There is also desire to have B2B tagging with customers tagging items purchased so the invoicing can be in the customers terminology rather than the seller terminology.
One of the advances in personal tagging portability and interoperability can easily be seen when we tag on one device and move the object to a second device or service (parts of this are not quite available yet). Some people will take a photo on their mobile phone and add quick tags like "sset" and others to a photo of a sunset. They send that photo to a service or move it to their desktop (or laptop) and import the photo and the tag goes along with it. The application sees the "sset" and knows the photo was transfered from that person's mobile device and knows it is their short code for "sunset" and expands the tag to sunset accordingly. The person then adds some color attribute tags to the photo and moves the photo to their photo sharing service of choice with the tags appended.
The current tools and services need tools and functionality to heal some of the messiness. This includes stemming to align versions of the same word (e.g. tag, tags, tagging, bookmark, bookmarking). Tag with disambiguation in mind by offering co-occurrence options (e.g. appleseed and anime or johnny or gardening or apple). String matching to identify facets for time and date, names (from your address book), products, secret tag terms (to have them blocked from sharing), etc. (similar to Stikkit and GMail).
Monitoring Tools
Enterprise is what the next development steps really need to take off (these needs also apply to the power knowledge worker as well). The monitoring tools for tags from others and around objects (URLs) really need to fleshed out and come to market. The tag monitoring tools need to become granular based on identity and co-occurance so to more tightly filter content. The ability to monitor a URL and how it is tagged across various services is a really strong need (there are kludgy and manual means of doing this today) particularly for simple and efficient tools (respecting the tagging service processing and privacy).
Analysis Tools
Enterprise and power knowledge workers also are in need of some solid analysis tools. These tools should be able to identify others in a service that have similar interests and vocabulary, this helps to surface people that should be collaborating. It should also look at shifts in terminology and vocabulary so to identify terms to be added to a taxonomy, but also provide an easy step for adding current emergent terms to related older tagged items. Identify system use patterns.
Just the Tip
We are still at the tip of the usefulness of tagging and the tools really need to make some big leaps. The demands are there in the enterprise marketplace, some in the enterprise are aware of them and many more a getting to there everyday as the find the value real and ability to improve the worklife and workflow for their knowledge workers is great.
The people using the tools, including enterprise need to grasp what is possible beyond that is offered and start asking for it. We are back to where we were in 2003 when del.icio.us arrived on the scene, we need new and improved tools that understand what we need and provide usable tools for those solutions. We are developing tag islands and silos that desperately need interoperability and portability to get real value out of these stranded tag silos around or digital life.
Reading Information and Patterns
The past few weeks and months the subject of reading, analysis, and visualization have been coming up a lot in my talking and chatting with people. These are not new subjects for me as they are long time passions. Part of the discussion the past few weeks have been focussed on what is missing in social bookmarking tools (particularly as one's own bookmarks and tags grows and as the whole service scales) as wells as group discussion monitoring tools, but this discussion is not the focus of this post. The focus is on reading, understanding, and synthesis of information and knowledge.
Not that Reading
I really want to focus on reading. Not exactly reading words, but reading patterns and recognizing patterns and flows to get understanding. After we learn to read a group of letters as a word we start seeing that group of letters as a shape, which is a word. It is this understanding of patterns that interact and are strung together that form the type of reading I have interest in.
Yesterday, Jon Udell posted about analyzing two gymnasts make turns. He was frustrated that the analysis on television lacked good insight (Jon is a former gymnast). Jon, who is fantastic at showing and explaining technologies and interactions to get to the core values and benefits as well as demoing needed directions, applied his great skill and craft on gymnastics. He took two different gymnasts doing the same or similar maneuver frame-by-frame. Jon knew how to read what each gymnast was doing and shared his understanding of how to read the differences.
Similarly a week or so ago an article about the Bloomberg Terminal fantasy redesign along with the high-level explanations and examples of the Bloomberg Terminal brought to mind a similar kind of reading. I have a few friends and acquaintances that live their work life in front of Bloomberg Terminals. The terminals are an incredible flood of information and views all in a very DOS-looking interface. There is a skill and craft in not only understanding the information in the Bloomberg Terminal, but also in learning to read the terminal. One friend I chatted with while he was working (years ago) would glance at the terminal every minute. I had him explain his glancing, which essentially was looking for color shifts in certain parts of the screen and then look for movement of lines and characters in other areas. He just scanned the screen to look for action or alerts. His initial pass was triage to then discern where to focus and possibly dive deeper or pivot for more related information.
The many of the redesign elements of the Bloomberg Terminals understood the reading and ability to understand vast information (in text) or augmented the interface with visualizations that used a treemap (most market analysts are very familiar with the visualization thanks to SmartMoney's useage). But, the Ziba design was sparse. To me it seemed like many of the market knowledge workers used to the Bloomberg Terminal and knew how to read it would wonder where their information had gone.
Simplicity and Reading with Experience
The Ziba solution's simplicity triggers the need in understanding the balance between simplicity just breaking down the complex into smaller easy to understand bits and growing into understanding the bits recollected in a format that is usable through recognition and learned reading skills. The ability to read patterns is learned in many areas of life in sport, craft, and work. Surfers look at the ocean waves and see something very different from those who do not surf in the ebb, flow, breaks, surface currents and under currents. Musicians not only read printed music but also hear music differently from non-musicians, but formally trained musicians read patterns differently from those who have just "picked it up". There has been a push in business toward data dashboards for many years, but most require having the right metrics and good data, as well as good visualizations. The dashboards are an attempt to provide reading information and data with an easier learning curve through visualization and a decreased reliance on deep knowledge.
Getting Somewhere with Reading Patterns
Where this leads it there is a real need in understanding the balance between simplicity and advanced interaction with reading patterns. There is also a need to understand what patterns are already there and how people read them, including when to adhere to these patterns and when to break them. When breaking the patterns there needs to be simple means of learning these new patterns to be read and providing the ability to show improved value from these new patterns. This education process can be short video screen shots, short how-to use the interface or interactions. Building pattern libraries is really helpful.
Next, identify good patterns that are available and understand why they work, particularly why they work for the people that use then and learn how people read them and get different information and understanding through reading the same interface differently. Look at what does not work and where improved tools are needed. Understand what information is really needed for people who are interested in the information and data.
 An example of this is Facebook, which has a really good home page for each Facebook member, it is a great digital lifestream of what my friends are doing. It is so much better at expressing flow and actions the people I have stated I have social interest in on Facebook than any other social web tool that came before Facebook. Relative to the individual level, Facebook fails with its interface of the information streams for its groups. Much of the content that is of interest in Facebook happens in the groups, but all the groups tell you is the number of new members, new messages, new videos, and new wall posts. There is much more valuable information tucked in there, such as who has commented that I normally interact with, state the threads that I have participated in that have been recently updated, etc.
An example of this is Facebook, which has a really good home page for each Facebook member, it is a great digital lifestream of what my friends are doing. It is so much better at expressing flow and actions the people I have stated I have social interest in on Facebook than any other social web tool that came before Facebook. Relative to the individual level, Facebook fails with its interface of the information streams for its groups. Much of the content that is of interest in Facebook happens in the groups, but all the groups tell you is the number of new members, new messages, new videos, and new wall posts. There is much more valuable information tucked in there, such as who has commented that I normally interact with, state the threads that I have participated in that have been recently updated, etc.
This example illustrates there needs to be information to read that has value and could tell a story. Are the right bits of information available that will aid understanding of the underlying data and stories? It the interface helpful? Is it easy to use and can it provide more advanced understanding? Are there easy to find lessons in how to read the interface to get the most information out of it?
Open Conversations and Privacy Needs for Business
I thought I would share the latest press bit around this joint, Thomas Vander Wal was quoted in Inc Magazine What's Next: Shout it Out Loud (or in the August 2007 issue beginning on page 69). The article focuses the need and desire for companies to share and be open with more of their data and information. Quite often companies are getting bit by their privacy around what they do (how their source their products/resources, who they donate money to, etc.) and rumors start. It is far more efficient and helpful to be open with that information, as it gets out anyway.
Ironically, in the same paper issue on page 26 there is a an article about When Scandal Knocks..., which includes a story about Jamba Juice and a blog post that inaccurately claimed it had milk in its products, which could have easily been avoided if Jamba Juice had an ingredients listing on its web site.
The Flip Side
There are two flip sides to this. One is the Apple converse, which is a rare example of a company really making a mythic organization out of its privacy. The second is companies really need privacy for some things, but the control of information is often too extreme and is now more harmful than helpful.
Viable Privacy
I have been working on a much longer post looking at the social software/web tools for and in the enterprise. Much of of the extreme openness touted in the new web charge is not a viable reality inside enterprise. There are a myriad of things that need to be private (or still qualify as valid reasons for many). The list include preparations for mergers and acquisitions, securities information dealings (the laws around this are what drive much of the privacy and are out dated), reorganizations (restructuring and layoffs, which organizations that have been open about this have found innovative solutions from the least likely places), personal employee records, as well as contractual reasons (advising or producing products for competitors in the same industry or market segment). Out side of these issues, which normally add up to under 30 to 40% of the whole of the information that flows through an organization, there is a lot of room for openness in-house and to the outside world.
Need for Enterprise Social Tools Grasping Partial Privacy
When we look at the consumer space for social software there are very few consumer tools that grasp social interaction and information sharing on a granular level (Ma.gnolia, Flickr, and the SixApart tools Vox and LiveJournal are the exceptions that always come to mind). But, many of the tools out there that are commonly used as examples of social web tools really fall down when business looks at them and thinks about privacy and selective sociality (small groups). The social web tools all around really need to grow up and improve in this area. As we are seeing the collaboration and social tools evolve to more viable options we start to see their more glaring holes that do not reflect the reality of human social interaction.
Closing the Gap
What we need is for companies to be more open so the marketplace is a more consumer and communicative environment, but we also need our still early social web tools to reflect our social realities that not everything is public and having tools that better fit those needs.
[Cross-posted at Personal InfoCloud: Open Converastions... with comments open on that posting.]
Sharing and Following/Listening in the Social Web
You may be familiar with my granular social network post and the postings around the Personal InfoCloud posts that get to personal privacy and personal management of information we have seen, along with the Come to Me Web, but there is an element that is still missing and few social web sites actually grasp the concept. This concept is granular in the way that the granular social network is granular, which focusses on moving away from the concept of "broad line friends" that focus on our interest in everything people we "friend", which is not a close approximation of the non-digital world of friend that we are lucky to find friends who have 80 percent common interests. This bit that is missing focusses on the sharing and following (or listening) aspects of our digital relationships. Getting closer to this will help filter information we receive and share to ease the overflow of information and make the services far more valuable to the people using them.
Twitter Shows Understanding
Twitter in its latest modifications is beginning to show that it is grasping what we are doing online is not befriending people or claiming friend, but we are "following" people. This is a nice change, but it is only part of the equation that has a few more variables to it, which I have now been presenting for quite a few years (yes and am finally getting around to writing about). The other variables are the sharing and rough facets of type of information we share. When we start breaking this down we can start understanding the basic foundation for building a social web application that can begin to be functional for our spheres of sociality.
Spheres of Sociality
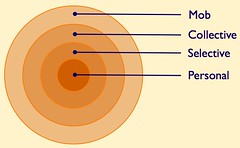 The Spheres of Sociality are broken into four concentric rings:
The Spheres of Sociality are broken into four concentric rings:
- Personal
- Selective
- Collective
- Mob
There are echos of James Surowiecki's Wisdom of Crowds in the Spheres of Sociality as they break down as follows. The personal sphere is information that is just for one's self and it is not shared with others. The selective sphere, which there may be many a person shares with and listens to, are closed groups that people are comfortable sharing and participating with on common interests (family, small work projects, small group of friends or colleagues, etc.). The collective sphere is everybody using that social tool that are members of it, which has some common (precise or vague) understanding of what that service/site is about. The last sphere is the mob, which are those people outside the service and are not participants and who likely do not understand the workings or terminology of the service.
These sphere help us understand how people interact in real life as well as in these social environments. Many of the social web tools have elements of some of these or all of these spheres. Few social web tools provide the ability to have many selective spheres, but this is a need inside most enterprise and corporate sites as there are often small project teams working on things that may or may not come to fruition (this will be a future blog post). Many services allow for just sharing with those you grant to be your followers (like Twitter, Flickr, the old Yahoo! MyWeb 2.0, and Ma.gnolia private groups, etc.). This selective and segmented group of friends needs a little more examination and a little more understanding.
Granular Sharing and Following
 The concepts that are needed to improve upon what has already been set in the Spheres of Sociality revolve around breaking down sharing and following (listening) into more discernible chunks that better reflect our interests. We need to do this because we do not always want to listen everything people we are willing to share with are surfacing. But, the converse is also true we may not want to share or need to share everything with people we want to follow (listen to).
The concepts that are needed to improve upon what has already been set in the Spheres of Sociality revolve around breaking down sharing and following (listening) into more discernible chunks that better reflect our interests. We need to do this because we do not always want to listen everything people we are willing to share with are surfacing. But, the converse is also true we may not want to share or need to share everything with people we want to follow (listen to).
In addition to each relationship needing to have sharing and listening properties, the broad brush painted by sharing and listening also needs to be broken down just a little (it could and should be quite granular should people want to reflect their real interests in their relationships) to some core facets. The core facets should have the ability to share and listen based on location, e.g. a person may only want to share or listen to people when they are in or near their location (keeping in mind people's location often changes, particularly for those that travel or move often). The location facet is likely the most requested tool particularly for those listening when people talk about Twitter and Facebook. Having some granular categories or tags to use as filters for sharing and listening makes sense as well. This can break down to simple elements like work, play, family, travel, etc. as broad categories it could help filter items from the sharing or listening streams and help bring to focus that which is of interest.
Breaking Down Listening and Sharing for Items
| Yourself | Others | |
|---|---|---|
| Share | Yes | Yes/No |
Where this gets us it to an ability to quickly flag the importance of our interactions with others with whom we share information/objects. Some things we can set on an item level, like sharing or just for self, and if sharing with what parameters are we sharing things. We will set the default sharing with ourself on so we have access to everything we do. This follows the Spheres of Sociality with just personal use, sharing with selective groups (which ones), share with the collective group or service, and share outside the service. That starts setting privacy of information that starts accounting for personal and work information and who could see it. Various services have different levels of this, but it is a rare consumer services that has the selective service sorted out (Pownce comes close with the options for granularity, but Flickr has the ease of use and levels of access. For each item we share we should have the ability to control access to that item, to just self or out across the Spheres of Sociality to the mob, if we so wish. Now we can get beyond the item level to presetting people with normative rights.
Listening and Sharing at the Person Level
| Others Settings | ||
|---|---|---|
| Listen/Follow | Yes | No |
| Granular Listen/Follow | Yes | No |
| Granular Share | Yes | No |
| Geo Listen/Follow | Yes | No |
| Geo Share | Yes | No |
We can set people with properties that will help use with default Sphere of Sociality for sharing and listening. The two directions of communication really must be broken out as there are some people we do not mind them listening to the selective information sharing, but we may not have interest in listening to their normal flow of offerings (optimally we should be able to hear their responses when they are commenting on items we share). Conversely, there may be people we want to listen to and we do not want to share with, as we may not know them well enough to share or they may have broken our privacy considerations in the past, hence we do not trust them. For various reasons we need to be able to decide on a person level if we want to share and listen to that person.
Granular Listening and Sharing
Not, only do we have needs and desires for filtering what we share and listen to on the person level, but if we have a means to set some more granular levels of sharing, even at a high level (family, work, personal relation, acquaintance, etc.). If we can set some of these facets for sharing and have them tied to the Spheres we can easily control who and what we share and listen to. Flickr does this quite well with the simple family, friends, contacts, and all buckets, even if people do not use them precisely as such as family and friends are the two selective buckets they offer to work with (most people I know do not uses them precisely as such with those titles, but it provides a means of selective sharing and listening).
Geo Listening and Sharing
Lastly, it is often a request to filter listening and sharing by geography/location access. There are people who travel quite a bit and want to listen and share with people that are currently local or will be local to them in a short period, but their normal conversations are not fully relevant outside that location. Many people want the ability not to listen to a person unless they are local, but when a person who has some relationship becomes local the conversation may want to be shared and/or listened to. These settings can be dependent on the granular listening and sharing parameters, or may be different.
Getting There...
So, now that this is out there it is done? Hmmm, if it were only so easy. The first step is getting developers of social web and social software to begin understanding the social relationships that are less broad lines and more granular and directional. The next step is a social interaction that people need to understand or that the people building the interfaces need to understand, which is if and how to tell people the rights granted are not reciprocal (it is seems to be a common human trait to have angst over non-reciprocal social interactions, but it is the digital realm that makes it more apparent that the flesh world).
Does IBM Get Folksonomy?
While I do not aim to be snarky, I often come off that way as I tend to critique and provide criticism to hopefully get the bumps in the road of life (mostly digital life) smoothed out. That said...
Please Understand What You Are Saying
I read an article this morning about IBM bringing clients to Second Life, which is rather interesting. There are two statements made by Lee Dierdorff and Jean-Paul Jacob, one is valuble and the other sinks their credibility as I am not sure they grasp what they actually talking about.
The good comment is the "5D" approach, which combines the 2D world of the web and the 3D world of Second Life to get improved search and relevance. This is worth some thinking about, not a whole lot as the solution as it is mentioned can have severe problems scaling. The solution of a virtual world is lacking where it does not augment our understanding much beyond 2D as it leaves out 4 of the 6 senses (it has visual and audio), and provides more noise into a pure conversation than a video chat with out the sensory benefits of video chat. The added value of augmented intelligence via text interaction is of interest.
I am not really sure that Lee Dierdorff actually gets what he is saying as he shows a complete lack of even partial understanding of what folksonomy is. Jacob states, "The Internet knows almost everything, but tells us almost nothing. When you want to find a Redbook, for instance, it can be very hard to do that search. But the only real way to search in 5D is to put a question to others who can ask others and the answer may or may not come back to you. It's part of social search. Getting information from colleagues (online) -- that's folksonomy." Um, no that is not folksonomy and not remotely close. It is something that stands apart and is socially augmented search that can viably use the diverse structures of a folksonomy to find relevant information, but asking people in a digital world for advise is not folksonomy. It has value and it is how many of us have used tools like Twitter and other social software that helps us keep those near in thought close (see Local InfoCloud). There could be a need for a term/word for that Jacob is talking about, but social search seems to be quite relevant as a term.
Related, I do have a really large stack of criticism for the IMB DogEar product that would improve it greatly. It needs a lot of improvement as a social bookmarking and folksonomy tool, but also from the social software interaction side there are things that really must get fixed for privacy interests in the enterprise before it really could be a viable solution. There are much better alternatives for social bookmarking inside an enterprise other than DogEar, which benefits from being part of the IBM social software stack Lotus Connections as the whole stack is decent together, but none of the parts are great, or even better than good by them self. DogEar really needs to get to a much more solid product quickly as their is a lot of interest now for this type of product, but it is only a viable solution if one is only looking at IBM products for solutions.
Understanding Taxonomy and Folksonmy Together
I deeply appreciate Joshua Porter's link to from his Taxonomies and Tags blog post. This is a discussion I have quite regularly as to the relation and it is in my presentations and workshops and much of my tagging (and social web) training, consulting, and advising focusses on getting smart on understanding the value and downfalls of folksonomy tagging (as well as traditional tagging - remember tagging has been around in commercial products since at least the 1980s). The following is my response in the comments to Josh' post...
Response to Taxonomy and Tags
Josh, thanks for the link. If the world of language were only this simple that this worked consistently. The folksonomy is a killer resource, but it lacks structure, which it crucial to disambiguating terms. There are algorithmic ways of getting close to this end, but they are insanely processor intensive (think days or weeks to churn out this structure). Working from a simple flat taxonomy or faceted system structure can be enabled for a folksonomy to adhere to.
This approach can help augment tags to objects, but it is not great at finding objects by tags as Apple would surface thousands of results and they would need to be narrowed greatly to find what one is seeking.
There was an insanely brilliant tool, RawSugar [(now gone thanks to venture capitalists pulling the plug on a one of a kind product that would be killer in the enterprise market)], that married taxonomy and folksonomy to help derive disambiguation (take appleseed as a tag, to you mean Johnny Appleseed, appleseed as it relates to gardening/farming, cooking, or the anime movie. The folksonomy can help decipher this through co-occurrence of terms, but a smart interface and system is needed to do this. Fortunately the type of system that is needed to do this is something we have, it is a taxonomy. Using a taxonomy will save processor time, and human time through creating an efficient structure.
Recently I have been approached by a small number of companies who implemented social bookmarking tools to develop a folksonomy and found the folksonomy was [initially] far more helpful than they had ever imagined and out paced their taxonomy-based tools by leaps and bounds (mostly because they did not have time or resources to implement an exhaustive taxonomy (I have yet to find an organization that has an exhaustive and emergent taxonomy)). The organizations either let their taxonomist go or did not replace them when they left as they seemed to think they did not need them with the folksonomy running. All was well and good for a while, but as the folksonomy grew the ability to find specific items decreased (it still worked fantastically for people refinding information they had personally tagged). These companies asked, "what tools they would need to start clearing this up?" The answer a person who understands information structure for ease of finding, which is often a taxonomist, and a tool that can aid in information structure, which is often a taxonomy tool.
The folksonomy does many things that are difficult and very costly to do in taxonomies. But taxonomies do things that folksonomies are rather poor at doing. Both need each other.
Complexity Increases as Folksonomies Grow
I am continually finding organizations are thinking the social bookmarking tools and folksonomy are going to be simple and a cure all, but it is much more complicated than that. The social bookmarking tools will really sing for a while, but then things need help and most of the tools out there are not to the point of providing that assistance yet. There are whole toolsets missing for monitoring and analyzing the collective folksonomy. There is also a need for a really good disambiguation tool and approach (particularly now that RawSugar is gone as a viable approach).