Off the Top: InfoCloud Entries
Showing posts: 1-15 of 159 total posts
Rebuilding My Note Taking and Management System and Model
The past many weeks I have been digging into a better note taking and management method, while also embracing what I have and my core underlying principles. A continual genre in YouTube I watch is around productivity, particularly around personal knowledge management methods and tools. A couple years back I ran into Zettelkasten Method, that comes from Niklas Luhmann, which focuses on his prolific reading and his card catalogue and related note taking system. Then a few months back I heard Jorge Arango’s interview with Beck Tench it drew Zettelkasten back into focus. The interview with Beck focussed on Tinderbox, which I love, but I also want mobile access to my notes from phone and tablet.
Early Exploration
I have been using Notion a little bit, but my only use the last few months is as an interstitial capture for YouTube and some other rich media. [I like Notion and it seems like a modern take on Podio and has a similar downfall of not sorting out an adaptive data structure for interoperability and consistency.] But, the communities that are interested in Notion became obsessed with Roam Research, so I looked at Roam. Roam and Notion are two vastly different approaches, which can complement each other but in to way replace each other. But, each has a similar faults, no API, no standard export for structured information, and fully cloud based. That is too many common failure points wrapped into one product (Notion is working on and API, which is really good). Roam bugged me most because it relies on an outline format but has no clue about OPML exporting, but worse has no good export model. The cloud based, which requires being connected and online is a model I really don’t like as, particularly if their isn’t a local sync nor standard data format model. What I really like about Roam is its block focussed format, that is akin to purple numbers model of small chunks that are addressable and reusable.
In this time of looking what a next generation of quick note taking would look like, but long used tool, NValt failed spectacularly, in that it would not find my directory where my 1,200+ notes were stored, nor could I add new notes. Fortunately all of my notes are in plain markdown text files, so all I was missing was my tagging of the files in NValt (Brett Terpstra who created NValt has been working on a new tool that can replace NValt but has been taking forever to show up and my need became immediate). This is one of the common reasons for owning my own notes and having them locally and not using somebody else’s model and framework. But, also using the [small apps loosely joined] model where many tools pointing at well formatted / structured data / information can function to their best ability and can use their strengths without breaking anything with the information / data.
Seriously Looking at Note Taking and Management Tools
I started looking at about five or six different note taking tools. I was building out a rough attribute model of tools to help see what each offered or didn’t. I am needing to write this up, but it started with watching Mike and Matty’s, Notion vs Roam vs Obsidian vs Remnote - How to best fit note taking app for you and using their criteria as a base, then building on it. Obsidian and Remnote were already on my list, but also included Zettelnote, Zettlr, and a couple that extended Tidlywiki for a Zettelkasten type model. I also included OmniOutliner as that has been (and will be) my core outlining tool that interplays well with OPML and I can back and forth with good mind mapping tools that also output and import OPML data standard. I also included DevonThink Pro as it is my long used (since 2005) note and information storage and smart search tool (it already was indexing my notes directories) that there is no chance I’m going to give up, but also knew it didn’t have the core functionality I was seeking, wiki-style back linking.
I did a quick test or Roam and ruled it out as it broke rules I try not to break, and it broke many of them (biggest one is know now you are going to exit before you enter anything and a lack of any structure nor API made it a giant risk I’ve been burned by too many times, but the developers have a lot of arrogance about their approach that far too often leads to disasters - sometimes the kindest, smartest, and solid planning people end up with disasters that I feel very badly about but arrogance and ignorant I don’t).
Zettlr and Remnote were next. But the setup took a bit more of me managing and building things and I know when I lose focus those may not be best choices for myself (my past self 15 years ago or more would have loved it and done well with it, but those days are not now).
Obsidian Ticks the Right Boxes and Adapts to My Existing Model
Obsidian is where I put some time. I pointed its “Vault” to my notes directory (and sub-directory) where I had my 1,200 markdown notes already (some of them were .txt extensions, which I did bulk extension swap on) and it could read everything perfectly. One of my first tests was adding backlinks to some of my social lenses and social scaling notes, which worked really well by making related elements connected. I started capturing my notes about what I was doing in Obsidian and the ease of not only connecting things with backlinks, but having the ability to set empty node wiki links (many notes with the same link to a note / page that doesn’t exist yet, but have the same link to it) and then being able to use backlink following from that non-existent notes link list of things pointing to it was insanely valuable.
I have quite a few book list and book note pages already and I started linking them and linking authors and making author pages. I also found I was wanting note page templates for simple book pages in a Zettelkasten model, a book notes template, author / creator template, and a few others. I created these from existing structured notes I’ve used for years and put the outlines in TextExpander using a simple input line or two to label all of the headers with author name or other name.
I started typing out my notes and highlights from books I’ve read and annotated over the years and after the first three or so books I was deeply hooked.
The Use Where Obsidian Showed I was Hooked
Where I knew I was sold was this last weekend I went back to one of Matt Webb’s blog posts on Small Groups that is dense and has links out to great resources. I captured my initial notes on Matt’s post, and annotated relating to his sections. But, I also quickly dug through the linked materials and created and filled out structured note pages for those as well. The James Mullholland post on Small Groups was fantastic and it spidered out to more related resources, so I followed those and took notes. All of this was cross-linked and back-linked and fleshed out small group notes that I have been building as part of social scaling I’ve been writing on and presenting (talks and workshops) for years. The small group size they focus on is roughly team size, but not a team. Both of these are cooperative social models, which scale from teams, groups (small to large groups with similar social interaction models, but the dynamics shift quite a bit around 75 people and break fully about 300 to 500 people), community (everybody inside a firewall or inside an walled off construct), and network (inside and outside a firewall - so for business it is customers, contractors, consultants, vendors, etc. where there needs to be a safe model for sharing information with shared goals as different roles with their purpose come together for back and forth exchange) - more can be found in my related write-up 5 Core Insights for Community Platforms Today.
This note taking and contextualizing and cross linking to rip through and gut a series of related and interrelated pieces has been something I’ve long looked for and wanted. Many dog years ago in college I took reading notes on note cards with citations and context. When writing a paper / essay I would assemble the note cards in an order that could tell a story. Then I would build an outline in WordStar and type in the quotes. Then I would write the narrative and wrapper. Obsidian is starting to get at that, but ripping through a resource to pull out highlights, quotes, annotations, and notes is utterly fantastic. It gives me a solid resource to easily pull together ideas and supporting information.
Other Obsidian Capabilities
Obsidian can show two note pages at once so to easily copy book citation information from the structured book note file into the book note page. The multiple notes in panels also works well for copying quotes to quote pages and cross linking.
Using Obsidian and Still Working from Mobile and Tablet
The mobile use essential had been broken for a bit after Dropbox stopped supporting softlinks in Mac and requiring that to be native in Dropbox and doing the softlink from the Mac to Dropbox. I moved the directory to Dropbox, which leaves a copy locally usable should something happen to Dropbox and added a softlink for local backups. I pointed DevonThink to this directory to index and I was back running. Now I can use Drafts to take a quick note from my iOS devices and push it to the notes directory (later go back and fix the file name) and I have good inbound notes and can use backlinks (which I test later). This method also works for share sheet to Drafts from Overcast or YouTube and having the link to the media and the notes all pulled in.
Happiness with notes has been missing for a while, perhaps happiness has returned.
Resources
Broken Decade Precedes It Works Decade
I had long forgotten this Carl Steadman response to Michael Sippy’s “Just One Question - What do you want for Christmas”, but the response from 1997 is fantastic and frames the 1990s as the broken decade. (I’ll wait for you to go read it)
I’m not so sure that Carl’s broken decade got better in the first half of the 2000 decade, but it really started to. We are much farther along now. Our consumer world started to improve quite a bit and slowly business systems and services are slowly improving. The initial part of Carl’s rant focusses on the number of steps to get something going. Once it is working the steps are still clunky.
Carl gets in a great rant about time and how broken it was in the 90s within technology (calendaring and syncing is still a beast and likely to for a bit longer - you understand the problem sets and pain points if you have ever tried to build syncing). With calendaring and its related activities we now have Tempo, which is freakishly close to the next step scenario I used in many of the Come to Me Web presentations and Personal InfoCloud presentations from 2003 through 2007 (I’ve been getting requests to represent them as this is what more and more developers and designers are dealing with today and need to have a better foundation to think through them). There was an internal Yahoo presentation (and follow on day of deep discussions and conversations) with a version of the Personal InfoCloud and Come to me Web flow that is nearly identical to the Tempo app video scenario and ones spelled out in Robert Scoble’s interview with Tempo CEO, which is utterly awesome that it is getting built out some 10 years later (we had the technology and tools to do this in 2004 and beyond).
Carl’s rant gets worn away over time though consumer devices, services, and applications. The refocus on ease of use and particularly the use through mobile, which requires a very different way of thinking and considering things. It thinking through design, the dependancies, and real user needs (all while keeping in mind the attention issues, screen size, networking, and device limitations). The past couple years mobile finally caught on with mainstream users and people doing real work on the mobile and tablets - Box 40% mobile access of files stored there over the last couple years. Many other business vendors have had mobile use rates of their services from mobile over the past two years. When talking to users they opt for mobile solutions over their full enterprise tools as they are much easier to use, which quickly translates into getting more work done. As Bernd Christiansen of Citrix stated in an onstage interview the employee’s most productive part of the day is often the walk from their car to the front door of the office working on their mobile devices.
This world is not fully better and fully easy to use from the days of Carl’s rant, but it is getting better. We still have quite a ways to go.
Late to Realizing Ovi Maps Does Exactly What I Wish
I been a big fan of Nokia's mapping solution built into its smart phones, Ovi Maps as it provides the best mobile turn by turn directions I've seen on any mobile device. But, this is largely because Nokia owns Navteq, which has long been the leader for on board mapping and driving solutions.
That FINALLY! Moment Reached
While I have been incredibly impressed with the Ovi mapping on my Nokia E72 device and often use the Ovi resources on the web, I hit that finally, somebody got this right moment with Ovi over the weekend. While, many web mapping solutions allow you to save favorites on the web getting those to sync to your mobile device, with your directions has been left out of most of these solutions (I have been complaining to friends at Google, Yahoo, and elsewhere for many years that this is a no-duh next step). Well, it seems Ovi figured this out quite a while back. (I noticed Google Mobile Maps provided this at the end of 2009, but have never been able to get it to work, even on my supported Symbian device.)
The simplicity and ease with with Nokia's Ovi pulls this off is rather stunning. With this aha moment, I feel like I was the last one to see this and sort it out, but in chats with other mobile maps and navigation users, they have been pained waiting for exactly this functionality, as most people it seems will get a location link and add it to their desktop maps (particularly for travel) but that does them little good as they don't take their desktop or open laptop into the car with them, they take their mobile. Understanding context of use is incredibly valuable.
Now may be a good time to check your device's capability, although iPhone does not seem to have this functionality supported by Google maps (surprised?).
Closing Delicious? Lessons to be Learned
There was a kerfuffle a couple weeks back around Delicious when the social bookmarking service Delicious was marked for end of life by Yahoo, which caused a rather large number I know to go rather nuts. Yahoo, has made the claim that they are not shutting the service down, which only seems like a stall tactic, but perhaps they may actually sell it (many accounts from former Yahoo and Delicious teams have pointed out the difficulties in that, as it was ported to Yahoo�s own services and with their own peculiarities).
Redundancy
Never the less, this brings-up an important point: Redundancy. One lesson I learned many years ago related to the web (heck, related to any thing digital) is it will fail at some point. Cloud based services are not immune and the network connection to those services is often even more problematic. But, one of the tenants of the Personal InfoCloud is it is where you keep your information across trusted services and devices so you have continual and easy access to that information. Part of ensuring that continual access is ensuring redundancy and backing up. Optimally the redundancy or back-up is a usable service that permits ease of continuing use if one resource is not reachable (those sunny days where there's not a cloud to be seen). Performing regular back-ups of your blog posts and other places you post information is valuable. Another option is a central aggregation point (these are long dreamt of and yet to be really implemented well, this is a long brewing interest with many potential resources and conversations).
With regard to Delicious I�ve used redundant services and manually or automatically fed them. I was doing this with Ma.gnol.ia as it was (in part) my redundant social bookmarking service, but I also really liked a lot of its features and functionality (there were great social interaction design elements that were deployed there that were quite brilliant and made the service a real gem). I also used Diigo for a short while, but too many things there drove me crazy and continually broke. A few months back I started using Pinboard, as the private reincarnation of Ma.gnol.ia shut down. I have also used ZooTool, which has more of a visual design community (the community that self-aggregates to a service is an important characteristic to take into account after the viability of the service).
Pinboard has been a real gem as it uses the commonly implemented Delicious API (version 1) as its core API, which means most tools and services built on top of Delicious can be relatively easily ported over with just a change to the URL for source. This was similar for Ma.gnol.ia and other services. But, Pinboard also will continually pull in Delicious postings, so works very well for redundancy sake.
There are some things I quite like about Pinboard (some things I don�t and will get to them) such as the easy integration from Instapaper (anything you star in Instapaper gets sucked into your Pinboard). Pinboard has a rather good mobile web interface (something I loved about Ma.gnol.ia too). Pinboard was started by co-founders of Delicious and so has solid depth of understanding. Pinboard is also a pay service (based on an incremental one time fee and full archive of pages bookmarked (saves a copy of pages), which is great for its longevity as it has some sort of business model (I don�t have faith in the �underpants - something - profit� model) and it works brilliantly for keeping out spammer (another pain point for me with Diigo).
My biggest nit with Pinboard is the space delimited tag terms, which means multi-word tag terms (San Francisco, recent discovery, etc.) are not possible (use of non-alphabetic word delimiters (like underscores, hyphens, and dots) are a really problematic for clarity, easy aggregation with out scripting to disambiguate and assemble relevant related terms, and lack of mainstream user understanding). The lack of easily seeing who is following my shared items, so to find others to potentially follow is something from Delicious I miss.
For now I am still feeding Delicious as my primary source, which is naturally pulled into Pinboard with no extra effort (as it should be with many things), but I'm already looking for a redundancy for Pinboard given the questionable state of Delicious.
The Value of Delicious
Another thing that surfaced with the Delicious end of life (non-official) announcement from Yahoo was the incredible value it has across the web. Not only do people use it and deeply rely on it for storing, contextualizing links/bookmarks with tags and annotations, refinding their own aggregation, and sharing this out easily for others, but use Delicious in a wide variety of different ways. People use Delicious to surface relevant information of interest related to their affinities or work needs, as it is easy to get a feed for not only a person, a tag, but also a person and tag pairing. The immediate responses that sounded serious alarm with news of Delicious demise were those that had built valuable services on top of Delicious. There were many stories about well known publications and services not only programmatically aggregating potentially relevant and tangential information for research in ad hoc and relatively real time, but also sharing out of links for others. Some use Delicious to easily build �related information� resources for their web publications and offerings. One example is emoted by Marshall Kirkpatrick of ReadWriteWeb wonderfully describing their reliance on Delicious
It was clear very quickly that Yahoo is sitting on a real backbone of many things on the web, not the toy product some in Yahoo management seemed to think it was. The value of Delicious to Yahoo seemingly diminished greatly after they themselves were no longer in the search marketplace. Silently confirmed hunches that Delicious was used as fodder to greatly influence search algorithms for highly potential synonyms and related web content that is stored by explicit interest (a much higher value than inferred interest) made Delicious a quite valued property while it ran its own search property.
For ease of finding me (should you wish) on Pinboard I am http://pinboard.in/u:vanderwal
----
Good relevant posts from others:
Where Good Ideas Come From - Finally Arriving
I don't think I have been awaiting a book for so long with so much interest as I am for Steven Berlin Johnson's (SBJ) new book, Where Good Ideas Come From: The Natural History of Innovation.
Why?
Ever since I read SBJ's book Emergence: The Connected Lives of Ants, Brains, Cities, and Software I was impressed how he pulled it together. I was even more impressed with how the book that followed, Mind Wide Open: Your Brain and the Neuroscience of Everyday Life (my notes from one piece of this book that really struck me is found in the post The User's Mind and Novelty). During all of this SBJ was writing about how he was writing and pulling notes together. On his personal blog he has talked often about DevonThink and how he uses it (this greatly influenced my trying it and purchasing it many years back and is the subject of a recent post of mine As If Had Read). This sharing about how he keeps notes of his own thoughts and works though ideas that go from tangents and turn into solid foundations for great understanding. It was this fascination that I included Steven as one of the people I would really like to meet, with the reasoning, "I like good conversation and the people that have provided great discovery through reading their writings often trigger good conversation that drives learning." (from Peter J. Bogaards interview with me for InfoDesign in July 2004).
The Sneak Preview Webinar
Today (Thursday 30 September 2010 as of this writing) Steven provided a webinar for those who had pre-ordered copies of his new book. It contains everything I have been expecting the book to have and have wished he would right up and put in a book over the last 6 to 7 years of wishing. He brings into the book the idea of the commonplace book, which I have been mulling over since I read it (I may be a bit obsessed with it as it ties in neatly with some other things I have been mulling about for a long time, like the Personal InfoCloud as written up in It is Getting Personal and many presentations going back into 2003, if not farther).
One of the great ideas that came out in the webinar was the idea of taking reading vacations to just take time off and read and focus on the reading and the ideas that come out of that reading and the ideas that are influenced by it. Steven talked about companies like Google and their 20% projects. But, what if companies gave employees paid time to read and focus on that. Read, learn, challenge what you know, expand your own understanding, mix what you have known and challenge it with new ideas and challenges and viewpoints. I think this is not only a good idea, but a great idea. Too many ideas have yet to be born and far too many "thought leaders" haven't evolved or challenged their thoughts in a long long time.
Yes, I can not wait to get this book in my hands and read. I am hoping the webinar will be made available more broadly as it is a gem as well.
As If Had Read
The idea of a tag "As If Had Read" started as a riff off of riffs with David Weinberger at Reboot 2008 regarding the "to read" tag that is prevalent in many social bookmarking sites. But, the "as if had read" is not as tongue-in-cheek at the moment, but is a moment of ah ha!
I have been using DevonThink on my Mac for 5 or more years. It is a document, note, web page, and general content catch all that is easily searched. But, it also pulls out relevance to other items that it sees as relevant. The connections it makes are often quite impressive.
My Info Churning Patterns
I have promised for quite a few years that I would write-up how I work through my inbound content. This process changes a lot, but it is back to a settled state again (mostly). Going back 10 years or more I would go through my links page and check all of the links on it (it was 75 to 100 links at that point) to see if there was something new or of interest.
But, that changed to using a feedreader (I used and am back to using Net News Wire on Mac as it has the features I love and it is fast and I can skim 4x to 5x the content I can in Google Reader (interface and design matters)) to pull in 400 or more RSS feeds that I would triage. I would skim the new (bold) titles and skim the content in the reader, if it was of potential interest I open the link into a browser tab in the background and just churn through the skimming of the 1,000 to 1,400 new items each night. Then I would open the browser to read the tabs. At this stage I actually read the content and if part way through it I don't think it has current or future value I close the tab. But, in about 90 minutes I could triage through 1,200 to 1,400 new RSS feed items, get 30 to 70 potential items of value open in tabs in a browser, and get this down to a usual 5 to 12 items of current or future value. Yes, in 90 minutes (keeping focus to sort the out the chaff is essential). But, from this point I would blog or at least put these items into Delicious and/or Ma.gnolia or Yahoo MyWeb 2.0 (this service was insanely amazing and was years ahead of its time and I will write-up its value).
The volume and tools have changed over time. Today the same number of feeds (approximately 400) turn out 500 to 800 new items each day. I now post less to Delicious and opt for DevonThink for 25 to 40 items each day. I stopped using DevonThink (DT) and opted for Yojimbo and then Together.app as they had tagging and I could add my context (I found my own context had more value than DevonThink's contextual relevance engine). But, when DevonThink added tagging it became an optimal service and I added my archives from Together and now use DT a lot.
Relevance of As if Had Read
But, one of the things I have been finding is I can not only search within the content of items in DT, but I can quickly aggregate related items by tag (work projects, long writing projects, etc.). But, its incredible value is how it has changed my information triage and process. I am now taking those 30 to 40 tabs and doing a more in depth read, but only rarely reading the full content, unless it is current value is high or the content is compelling. I am acting on the content more quickly and putting it into DT. When I need to recall information I use the search to find content and then pull related content closer. I not only have the item I was seeking, but have other related content that adds depth and breath to a subject. My own personal recall of the content is enough to start a search that will find what I was seeking with relative ease. But, were I did a deeper skim read in the past I will now do a deeper read of the prime focus. My augmented recall with the brilliance of DevonThink works just as well as if I had read the content deeply the first time.
Catching Up On Personal InfoCloud Blog Posts
Things here are a little quiet as I have been in writing mode as well as pitching new work. I have been blogging work related items over at Personal InfoCloud, but I am likely only going to be posting summaries of those pieces here from now on, rather than the full posts. I am doing this to concentrate work related posts, particularly on a platform that has commenting available. I am still running my own blogging tool here at vanderwal.net I wrote in 2001 and turned off the comments in 2006 after growing tired of dealing comment spam.
The following are recently posted over at Personal InfoCloud
SharePoint 2007: Gateway Drug to Enterprise Social Tools
SharePoint 2007: Gateway Drug to Enterprise Social Tools focusses on the myriad of discussions I have had with clients of mine, potential clients, and others from organizations sharing their views and frustrations with Microsoft SharePoint as a means to bring solid social software into the workplace. This post has been brewing for about two years and is now finally posted.
Optimizing Tagging UI for People & Search
Optimizing Tagging UI for People and Search focuses on the lessons learned and usability research myself and others have done on the various input interfaces for tagging, particularly tagging with using multi-term tags (tags with more than one word). The popular tools have inhibited adoption of tagging with poor tagging interaction design and poor patterns for humans entering tags that make sense to themselves as humans.
LinkedIn: Social Interaction Design Lessons Learned (not to follow)
I have a two part post on LinkedIn's social interaction design. LinkedIn: Social Interaction Design Lessons Learned (not to follow) - 1 of 2 looks at what LinkedIn has done well in the past and had built on top. Many people have expressed the new social interactions on LinkedIn have decreased the value of the service for them.
The second part, LinkedIn: Social Interaction Design Lessons Learned (not to follow) - 2 of 2 looks at the social interaction that has been added to LinkedIn in the last 18 months or so and what lessons have we as users of the service who pay attention to social interaction design have learned. This piece also list ways forward from what is in place currently.
Enterprise 2.0 Boston - After Noah: What to do After the Flood (of Information)
I am looking forward to being at the Enterprise 2.0 Conference in Boston from June 10 to June 12, 2008. I am going to be presenting on June 10, 2008 at 1pm on After Noah: Making Sense of the Flood (of Information). This presentation looks at what to expect with social bookmarking tools inside an organization as they scale and mature. It also looks at how to manage the growth as well as encourage the growth.
Last year at the same Enterprise 2.0 conference I presented on Bottom-up Tagging (the presentation is found at Slideshare, Bottom-up All the Way Down: How Tags Help Businesses Organize, which has had over 8,800 viewing on Slideshare), which was more of a foundation presentation, but many in the audience were already running social bookmarking services in-house or trying them in some manner. This year my presentation is for those with an understanding of what social bookmarking and folksonomy are and are looking for what to expect and how to manage what is happening or will be coming along. I will be covering how to manage heavy growth as well as how to increase adoption so there is heavy usage to manage.
I look forward to seeing you there. Please say hello, if you get a chance.
Getting Info into the Field with Extension
This week I was down in Raleigh, North Carolina to speak at National Extension Technology Conference (NETC) 2008, which is for the people running the web and technology components for what used to be the agricultural extension of state universities, but now includes much more. This was a great conference to connect with people trying to bring education, information, and knowledge services to all communities, including those in rural areas where only have dial-up connectivity to get internet access. The subject matter presented is very familiar to many other conferences I attend and present at, but with a slightly different twist, they focus on ease of use and access to information for everybody and not just the relatively early adopters. The real values of light easy to use interfaces that are clear to understand, well structured, easy to load, and include affordance in the initial design consideration is essential.
I sat in on a few sessions, so to help tie my presentation to the audience, but also listen to interest and problems as they compare to the organizations I normally talk to and work with (mid-size member organizations up to very large global enterprise). I sat in on a MOSS discussion. This discussion about Sharepoint was indiscernible from any other type of organization around getting it to work well, licensing, and really clumsy as well as restrictive sociality. The discussion about the templates for different types of interface (blogs and wikis) were the same as they they do not really do or act like the template names. The group seemed to have less frustration with the wiki template, although admitted it was far less than perfect, it did work to some degree with the blog template was a failure (I normally hear both are less than useful and only resemble the tools in name not use). [This still has me thinking Sharepoint is like the entry drug for social software in organizations, it looks and sounds right and cool, but is lacking the desired kick.]
I also sat down with the project leads and developers of an eXtension wide tool that is really interesting to me. It serves the eXtension community and they are really uncoupling the guts of the web tools to ease greater access to relevant information. This flattening of the structures and new ways of accessing information is already proving beneficial to them, but it also has brought up the potential to improve ease some of the transition for those new to the tools. I was able to provide feedback that should provide a good next step. I am looking forward to see that tool and the feedback in the next three to six months as it has incredible potential to ease information use into the hands that really need it. It will also be a good example for how other organizations can benefit from similar approaches.
Comments are open (with usual moderation) at this post at Getting Info into the Field with Extension :: Personal InfoCloud.
Selective Sociality and Social Villages
The web provides wonderful serendipity on many fronts, but in this case it brought together two ideas I have been thinking about, working around, and writing about quite a bit lately. The ideas intersect at the junction of the pattern of building social bonds with people and comfort of know interactions that selective sociality brings.
The piece that struck me regarding building and identifying a common bond with another person came out of Robert Paterson's "Mystery of Attraction" post (it is a real gem). Robert describes his introduction and phases of getting to know and appreciate Luis Suarez (who I am a huge fan of and deeply appreciate the conversations I have with him). What Robert lays out in his introduction (through a common friend on-line) is a following of each other's posts and digital trail that is shared out with others. This builds an understanding of each others reputation in their own minds and the shared interest. Upon this listening to the other and joint following they built a relationship of friendship and mutual appreciation (it is not always mutual) and they began to converse and realized they had a lot more in common.
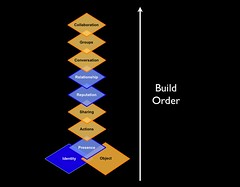 What Robert echos is the Elements in Social Software and its build order. This build order is common in human relationships, but quite often social software leaves out steps or expects conversations, groups, and collaboration to happen with out accounting for the human elements needed to get to this stage. Quite often the interest, ideas, and object (all social objects) are the stimulus for social interaction as they are the hooks that connect us. This is what makes the web so valuable as it brings together those who are near in thought and provides a means to connect, share, and listen to each other. I really like Robert's analogy of the web being like university.
What Robert echos is the Elements in Social Software and its build order. This build order is common in human relationships, but quite often social software leaves out steps or expects conversations, groups, and collaboration to happen with out accounting for the human elements needed to get to this stage. Quite often the interest, ideas, and object (all social objects) are the stimulus for social interaction as they are the hooks that connect us. This is what makes the web so valuable as it brings together those who are near in thought and provides a means to connect, share, and listen to each other. I really like Robert's analogy of the web being like university.
Selective Sociality of Villages
The piece that resonated along similar threads to Robert's post is Susan Mernit's "Twitter & Friend Feed: The Pleasure of Permissions". Susan's post brings to light the value of knowing who you are sharing information with and likes the private or permission-based options that both Twitter and FriendFeed offer. This selective sociality as known Local InfoCloud of people and resources that are trusted and known, which we use as resources. In this case it is not only those with whom we listen to and query, but those with whom we share. This knowing who somebody is (to some degree) adds comfort, which is very much like Robert Patterson and Luis Suarez#039; villages where people know each other and there is a lot of transparency. Having pockets where our social armor is down and we can be free to share and participate in our lives with others we know and are familiar to us is valuable.
I am found these two pieces quite comforting as they reflect much of what I see in the physical community around me as well as the work environments I interact with of clients and collaborators. The one social web service I have kept rather private is Twitter and I really want to know who someone is before I will accept them as a connection. This has given me much freedom to share silly (down right stupid - in a humorous way) observations and statements. This is something I hear from other adults around kids playgrounds and practices of having more select social interactions on line in the services and really wanting to connect with people whom they share interests and most often have known (or followed/listened to) for sometime before formally connecting. Most often these people want to connect with the same people on various services they are trying out, based on recommendation (and often are leaving a service as their friends are no longer there or the service does not meet their needs) of people whom they trust. This is the core of the masses who have access and are not early adopters, but have some comfort with the web and computers and likely make up 80 to 90 percent of web users.
[Comments are open (with moderation as always) on this post at Selective Sociality and Social Villages :: Personal InfoCloud]
Understanding Collective and Collaborative
I have finally blogged about the different between the two terms of collaborative and collective, which has been something bugging me for some time. Comments there are open, but are moderated (as they always have been). Those who have been to any of my workshops in the past year or so will see familiar information. Hopefully, the post will help those discussing and crafting social tools for the general web (or mobile) or large organizations will read and work to grasp the difference. I have had plenty of academics, researchers, and service developers push me to make this public for far too long so to start getting the misunderstanding around the two terms corrected.
Data Sharing Summit Announced
The Bay Area the week of May 12 has a couple great events that many who read this blog should be attending. I will be in Las Vegas (putting on a Enterprise 2.0 Jumpstart workshop with Jevon MacDonald) for part of the week, but should be in the Bay Area for the remainder of the time (at least that is the plan at the moment).
Data Sharing Summit
Following on the success and interest from the event last year is the Data Sharing Summit held April 15th at the Computer History Museum in Mountain View. Data sharing is getting to be the next hot spot that social web services and enterprise tool makers really much deal with as people are not satisfied living in their single walled gardens that inhibit their ability to share, find, hold on to, and refind information, media, and knowledge that is of interest or needed by them. Understanding the limits of the partitioned spaces and embracing more open (particularly securely open) uses of the contributions made by the tools and services participants is vitally important as the participants and system owners are realizing there is rich value to be gained from a much better understanding of these interactions with participants and other services.
We are living in a digital sharing realm that was dreamed up by designers and developers scratching their own itch and in doing so the tools are self contained and not living in a social ecosystem that is based on intelligent interactions. This will likely be the focus of the discussion as people on all sides are working to vastly improve the value of their services and tools and the value that people get from using them with other tools. This is not an event to sell products, but an event for smart people to discuss where things are, where they are going (or went when we were not looking), how to progress with opening up in a manner that all the parties gain value (understanding what and where the value resides is critical), and how we can all move forward.
I will see you there, right?
Social Computing Summit in Miami, Florida in April, 2008
ASIS&T has a new event they are putting on this year, the Social Computing Summit in Miami, Florida on April 10-11, 2008 (a reminder page is up at Yahoo's Upcoming - Social Computing Summit). The event is a single-track event on both days with keynote presentations, panels, and discussion.
The opening keynote is by Nancy Baym. I have been helping assist with organization of the Social Computing Summit and was asked by the other organizers to speak, which I am doing on the second day. The conference is a mix of academic, consumer, and business perspectives across social networking, politics, mobile, developing world, research, enterprise, open social networks (social graph and portable social networks) as well as other subjects. The Summit will be a broad view of the digital social world and the current state of understanding from various leaders in social computing.
There is an open call for posters for the event that closes on February 25, 2008. Please submit as this is looking to be a great event and more perspectives and expertise will only make this event more fantastic.
DataPortability Video is Place to Start Understanding
Marchall Kirkpatrick at ReadWriteWeb has posted a good background about New Video Explains the Basics of Data Portability. The DataPortability - Connect, Control, Share, Remix video is under 2 minutes in length and explains the reasons why the DataPoratbility.org group is important. It aims to ease the pain many are experiencing as they use more social media, social web services, social networks, and/or social computing services in their personal and work life.
Control
The biggest piece in this for me is control with translates to services respecting privacy wishes among other desires around trust and control of sharing. As Tom Raftery points out With the rising interest in, and use of Social Networks (FaceBook, Plaxo et al) there is growing unease in what those sites are doing with your data, never mind the inconvenience of uploading all your data every time you join a new site. The DataPortability.org aims to include in its focus data that is "shared between our chosen (and trusted) tools and vendors".
I have been working around the edges on a project whose aim is to respect these privacy wishes. This is one of the things that really needs to be at the core of all services entering into this market segment.
Ma.gnolia Goes Mobile
On Friday Ma.gnolia rolled out a mobile version of their site, M.gnolia - Mobile Ma.gnolia. This had me really excited as I now have access to my bookmarks in my pocket on my mobile. Ma.gnolia gives a quick preview in their blog post Ma.gnolia Blog: Flowers on the Go.
What Mobile Ma.gnolia Does and Does Not Do
First, off the mobile Ma.gnolia does not have easy bookmarking, which is not surprising given the state things in mobile browsers. I really do not see this as a huge downside. What I am head over heals happy about is access to my bookmarks (all 2800 plus). The mobile version allows searching through your own tags (if you are logged in). It currently has easy access to see that is newly bookmarked in Ma.gnolia groups you follow, your contact's bookmarks, popular bookmarks, your own tags, and your profile.
Mobile Site Bookmarks
One thing that is helpful for those that use mobile web browsing is having easy access to mobile versions of web sites. Yes, the iPhone and many smartphone users (I am in the Nokia camp with my well liked E61i) can easily browse and read regular web pages, but mobile optimized pages are quicker to load and have less clutter on a smaller screen. The iPhone, WebKit-based browsers (Nokia), Opera Mini, and other decent mobile web browsers all have eased mobile browsing use of regular webpages, but having a list of mobile versions is really nice.
Yesterday, Saturday, I created a Ma.gnolia Mobile Version Group so people can share web pages optimized for mobile devices (quicker/smaler downloads, smaller screens, less rich ads, etc.). One of the ways I was thinking people could use this is to find sites in this group then bookmark them for their own use with tags and organization that makes sense for themself. The aim is just to collect and share with others what you find helpful and valuable for yourself. This group will be monitored for spam as the rest of Ma.gnolia is (Ma.gnolia uses "rel="no-follow"" so there really is little value to spammers).
Ways You Can Use Mobile Ma.gnolia
This means if you tagged a store, restaurant, bar, transit site, or other item that has value when out walking around it is really nice to have quick access to it. It can also be a great way to read those items you have tagged "to read" (if you are a person that tags things in that manner) so you can read what you want in the doctor's office, bus, train, or wherever.
I have a lot of content I have bookmarked for locations I am work, live, and visit. When I come across something I want to remember (places to eat, drink, learn, hang, be entertained, etc.) I often dump them into the bookmarks. But, getting to this information has been painful from a mobile in the past. I am now starting to go back to things I have tagged with locations and add a "togo" tag so they are easier for me to find and use in the Ma.gnolia mobile interface. I have already added a bookmark for an museum exhibit that I really want to see that is not far from where I am. When a meeting is dropped, postponed, or runs short near the museum I can make a trip over and see it. There is so much information flowing through my devices and it is nice to be able to better use this info across my Personal InfoCloud in my trusted devices I have with me and use the information in context it is well suited for, when have stepped away from my desk or laptop.
I am looking forward to see where this goes. Bravo and deep thanks to the Larry and others at Ma.gnolia that made this happen!