Off the Top: Folksonomy Entries
Showing posts: 1-15 of 121 total posts
Rebuilding My Note Taking and Management System and Model
The past many weeks I have been digging into a better note taking and management method, while also embracing what I have and my core underlying principles. A continual genre in YouTube I watch is around productivity, particularly around personal knowledge management methods and tools. A couple years back I ran into Zettelkasten Method, that comes from Niklas Luhmann, which focuses on his prolific reading and his card catalogue and related note taking system. Then a few months back I heard Jorge Arango’s interview with Beck Tench it drew Zettelkasten back into focus. The interview with Beck focussed on Tinderbox, which I love, but I also want mobile access to my notes from phone and tablet.
Early Exploration
I have been using Notion a little bit, but my only use the last few months is as an interstitial capture for YouTube and some other rich media. [I like Notion and it seems like a modern take on Podio and has a similar downfall of not sorting out an adaptive data structure for interoperability and consistency.] But, the communities that are interested in Notion became obsessed with Roam Research, so I looked at Roam. Roam and Notion are two vastly different approaches, which can complement each other but in to way replace each other. But, each has a similar faults, no API, no standard export for structured information, and fully cloud based. That is too many common failure points wrapped into one product (Notion is working on and API, which is really good). Roam bugged me most because it relies on an outline format but has no clue about OPML exporting, but worse has no good export model. The cloud based, which requires being connected and online is a model I really don’t like as, particularly if their isn’t a local sync nor standard data format model. What I really like about Roam is its block focussed format, that is akin to purple numbers model of small chunks that are addressable and reusable.
In this time of looking what a next generation of quick note taking would look like, but long used tool, NValt failed spectacularly, in that it would not find my directory where my 1,200+ notes were stored, nor could I add new notes. Fortunately all of my notes are in plain markdown text files, so all I was missing was my tagging of the files in NValt (Brett Terpstra who created NValt has been working on a new tool that can replace NValt but has been taking forever to show up and my need became immediate). This is one of the common reasons for owning my own notes and having them locally and not using somebody else’s model and framework. But, also using the [small apps loosely joined] model where many tools pointing at well formatted / structured data / information can function to their best ability and can use their strengths without breaking anything with the information / data.
Seriously Looking at Note Taking and Management Tools
I started looking at about five or six different note taking tools. I was building out a rough attribute model of tools to help see what each offered or didn’t. I am needing to write this up, but it started with watching Mike and Matty’s, Notion vs Roam vs Obsidian vs Remnote - How to best fit note taking app for you and using their criteria as a base, then building on it. Obsidian and Remnote were already on my list, but also included Zettelnote, Zettlr, and a couple that extended Tidlywiki for a Zettelkasten type model. I also included OmniOutliner as that has been (and will be) my core outlining tool that interplays well with OPML and I can back and forth with good mind mapping tools that also output and import OPML data standard. I also included DevonThink Pro as it is my long used (since 2005) note and information storage and smart search tool (it already was indexing my notes directories) that there is no chance I’m going to give up, but also knew it didn’t have the core functionality I was seeking, wiki-style back linking.
I did a quick test or Roam and ruled it out as it broke rules I try not to break, and it broke many of them (biggest one is know now you are going to exit before you enter anything and a lack of any structure nor API made it a giant risk I’ve been burned by too many times, but the developers have a lot of arrogance about their approach that far too often leads to disasters - sometimes the kindest, smartest, and solid planning people end up with disasters that I feel very badly about but arrogance and ignorant I don’t).
Zettlr and Remnote were next. But the setup took a bit more of me managing and building things and I know when I lose focus those may not be best choices for myself (my past self 15 years ago or more would have loved it and done well with it, but those days are not now).
Obsidian Ticks the Right Boxes and Adapts to My Existing Model
Obsidian is where I put some time. I pointed its “Vault” to my notes directory (and sub-directory) where I had my 1,200 markdown notes already (some of them were .txt extensions, which I did bulk extension swap on) and it could read everything perfectly. One of my first tests was adding backlinks to some of my social lenses and social scaling notes, which worked really well by making related elements connected. I started capturing my notes about what I was doing in Obsidian and the ease of not only connecting things with backlinks, but having the ability to set empty node wiki links (many notes with the same link to a note / page that doesn’t exist yet, but have the same link to it) and then being able to use backlink following from that non-existent notes link list of things pointing to it was insanely valuable.
I have quite a few book list and book note pages already and I started linking them and linking authors and making author pages. I also found I was wanting note page templates for simple book pages in a Zettelkasten model, a book notes template, author / creator template, and a few others. I created these from existing structured notes I’ve used for years and put the outlines in TextExpander using a simple input line or two to label all of the headers with author name or other name.
I started typing out my notes and highlights from books I’ve read and annotated over the years and after the first three or so books I was deeply hooked.
The Use Where Obsidian Showed I was Hooked
Where I knew I was sold was this last weekend I went back to one of Matt Webb’s blog posts on Small Groups that is dense and has links out to great resources. I captured my initial notes on Matt’s post, and annotated relating to his sections. But, I also quickly dug through the linked materials and created and filled out structured note pages for those as well. The James Mullholland post on Small Groups was fantastic and it spidered out to more related resources, so I followed those and took notes. All of this was cross-linked and back-linked and fleshed out small group notes that I have been building as part of social scaling I’ve been writing on and presenting (talks and workshops) for years. The small group size they focus on is roughly team size, but not a team. Both of these are cooperative social models, which scale from teams, groups (small to large groups with similar social interaction models, but the dynamics shift quite a bit around 75 people and break fully about 300 to 500 people), community (everybody inside a firewall or inside an walled off construct), and network (inside and outside a firewall - so for business it is customers, contractors, consultants, vendors, etc. where there needs to be a safe model for sharing information with shared goals as different roles with their purpose come together for back and forth exchange) - more can be found in my related write-up 5 Core Insights for Community Platforms Today.
This note taking and contextualizing and cross linking to rip through and gut a series of related and interrelated pieces has been something I’ve long looked for and wanted. Many dog years ago in college I took reading notes on note cards with citations and context. When writing a paper / essay I would assemble the note cards in an order that could tell a story. Then I would build an outline in WordStar and type in the quotes. Then I would write the narrative and wrapper. Obsidian is starting to get at that, but ripping through a resource to pull out highlights, quotes, annotations, and notes is utterly fantastic. It gives me a solid resource to easily pull together ideas and supporting information.
Other Obsidian Capabilities
Obsidian can show two note pages at once so to easily copy book citation information from the structured book note file into the book note page. The multiple notes in panels also works well for copying quotes to quote pages and cross linking.
Using Obsidian and Still Working from Mobile and Tablet
The mobile use essential had been broken for a bit after Dropbox stopped supporting softlinks in Mac and requiring that to be native in Dropbox and doing the softlink from the Mac to Dropbox. I moved the directory to Dropbox, which leaves a copy locally usable should something happen to Dropbox and added a softlink for local backups. I pointed DevonThink to this directory to index and I was back running. Now I can use Drafts to take a quick note from my iOS devices and push it to the notes directory (later go back and fix the file name) and I have good inbound notes and can use backlinks (which I test later). This method also works for share sheet to Drafts from Overcast or YouTube and having the link to the media and the notes all pulled in.
Happiness with notes has been missing for a while, perhaps happiness has returned.
Resources
The Sidebar is the New Back Bar
Back in the days when I had time to hangout with friends for drinks, many places had a “back bar” that was more quiet and private.
I haven’t been in the habit of posting here as much as I used to, but I still am putting things into Pinboard and somethings I flag with “linkfodder”, which is my relatively unique tag to pull out favorites. I use the API from Pinboard to pull the linkfodder tagged items into the sidebar here. Occasionally I annotate them and that is brought here as well. This sidebar mini blog feels sort of like the back bar, which is a little more quiet and calm and you can see some things of interest to me (if that is of interest to you) and track them down.
Mac and iOS Tagging with Brett Terpstra
If you are still following along here it is likely in hopes of something related to tagging or folksonomy (I have a stack of folksonomy and tagging things piled up, but not written-up) so today you win.
This week’s Mac Power Users is an interview on tagging with Brett Terpstra. This episode digs deep into what is coming in iOS and current state of tagging on Macs. While things are mostly tagging standards based, the implementations are still a bit on the manual and geek scripting side of things.
I am deeply excited about iOS getting tags that come over from Mac, which is why I have been tagging things for the past few years. I have been playing the long game with MacOS tagging in hopes that it would also sync to iOS. Years back I was really certain (the kind of certain driven by hope, more than knowing) Mac was going to provide a tag only option, which was going to be really good, as files have multiple contexts and tags can adapt for that reality (which is far closer to life than nested folders).
While we never got the world I swore was going to be the next logical step, or at least as an option, we do have something interesting now. It will be more capable and usable in the next few months with the iOS 11 and the next MacOS update, High Sierra. If this is your thing, give Brett’s sit down with MacSparky and Katie a go and you are more than likely going to find one or more tip to up your game, if not get much more out of it.
Inviewed on Shift Podcast
On Friday I had the pleasure of spending about an hour with two of my favorite people, Euan Semple and Megan Murray on the wonderful podcast, Shift. We covered tagging, taxonomies, meaning, power, and the future that we are all hurtling towards.
I am a big fan of their interviews (as their conversations between them are familiar from past conversations between us) with other. I still have a few to get to.
Blogfodder and Linkfodder
Not only do I have a blogfodder tag I use on my local drive and cross device idea repositories and writing spaces, but I have a linkfodder marker as well.
Blogfodder
Blogfodder are those things that are seeds of ideas for writing or are fleshed out, but not quite postable / publishable. As I wrote in Refinement can be a Hinderance I am trying to get back to my old pattern of writing regularly as a brain dump, which can drift to stream of consciousness (but, I find most of the things that inspire me to good thoughts and exploration are other’s expressions shared in a stream of consciousness manner). The heavy edit and reviews get in the way of thought and sharing, which often lead to interactions with others around those ideas. I am deeply missing that and have been for a few years, although I have had some great interactions the last 6 months or so.
I also use blogfodder as a tag for ideas and writing to easily search and aggregate the items, which I also keep track of in an outline in OmniOutliner. But, as soon as I have posted these I remove the blogfodder tag and use a “posted” tag and change the status in OmniOutliner to posted and place a link to the post.
Linkfodder
Linkfodder is a term I am using in bookmarking in Pinboard and other local applications. These started with the aim of being links I really want to share and bring back into the sidebar of this blog at vanderwal.net. I have also hoped to capture and write quick annotations for a week ending links of note post. That has yet to happen as I want to bring in all the months of prior linkfoddering.
I have been looking at Zeef to capture the feed from my Pinboard linkfodder page and use a Zeef widget in my blog sidebar. I have that running well on a test sight and may implement it soon here (it is a 5 minute task to do, but it is the “is it how I want to do it” question holding me back). In the past I used Delicious javascript, which the newest owners of Delicious gloriously broke in their great unknowing.
The Wrap
Both of these are helping filter and keep fleeting things more organized. And hopefully execution of these follows.
30 Days Had November
Well the attempt to blog every day in November didn’t get as much wind in its sails as I had hoped it would have. November had 30 days, but I had far fewer posts than 30. I didn’t get a new habit set. But, I am not yet deterred as I am keeping this attempt going.
One of the things I’ve thought about doing is doing a weekly link dump of items I found of interest through out the week. These are some of my favorite week end reads when I curl up with the laptop (or iPad), a cup of coffee and a blanket. I have long been a fan of Om’s weekend delivery of his 5 (or 7) things to read this weekend as they are nearly always high quality, in depth, and decent (meaning on the longer side) length. I’ve also grown to head toward Josh Ginter of “The Newsprint” weekly “The Sunday Edition” link dump of the week. Recently Michael Sippy has been back sharing on the web (just like the days of yore) and his Filtered Week series on Medium is an annotated link list gem.
One of the reasons I have been considering this (and actually tucking links away for posting) is the past few weeks I realized my blog’s link list on the side of this blog that was posted from Delicious is now dead and gone. The link roll that was a staple of Delicious from 2004 or so was nuked with many other helpful features and functionality that kept Delicious as one part of my workflow. I moved most of my social bookmarking to Pinboard a few years back, but I still fed Delicious and then Delicious fed Pinboard. Well, that was the case until the new owners of Delicious (sadly Delicious gets passed around the IT community like a hot potato with each new owner thinking they are going to update it and improve it, yet lack a rat’s clue of the basics nor how to keep (now kept) the workings that underpin many parts of the web running) fumbled things and Pinboard stopped automatically ingesting Delicious. I really missed the change at Pinboard (was heads down on a project when that happened), but now all my social bookmarking is happening there.
The lack of a link sidebar is the push to share things that I find as gems from the week. I could repoint the Delicious javascript to Pinboard, but Pinboard also captures all my starred / favorited items (I don’t use starring in Twitter as a favorite, but more of a hook for things to hold on to and / or come back to) and things favorited in Instagram, and imports from other services. Pinboard, because I use the paid archive service is an endpoint that serves also as a place to do full text search of the items bookmarked there. Until I can sort out a good filter or means of tagging in my workflow, I am keeping the link list off the sidebar. But, in its place I am likely going to do a weekly link list.
Brett Terpstra Focusses on His Work Full-time
I have been a fan of Brett Terpstra for some time. I found his site through a few buds who focus on productivity and personal workflows (including scripting). I have followed his Systematic podcast since the first episode and have found it is the one podcast I listen to when my weekly listening dwindles to just one podcast. His nvALT became an app that is always running and where a lot of writing snippets get stored on my Mac (that content I also reach on my iOS devices to edit and extend). His Marked2 app not only is my Markedown viewer, but a rather good writing analysis tool.
Not only all of this but Brett is a tagger and not only tags, belives tagging is helpful for personal filtering and workflow, but has built tools to greater extend tagging in and around Mac and iOS. If you talk folksonomy and pull the third leg of it, person / identity back into just your own perspective and keep the tag and objects in place you have the realm that Brett focusses and pushes farther for our own personal benefit.
Brett Steps Out to Focus on His Work
This week I have been incredibly happy to learn that Brett moved out of his daytime job to and his new job is to focus on his products, podcast, writing, and new projects and products. This is great news for all of us. Brett took this step before, but we can help him keep these tools and services flowing by supporting him.
If you have benefitted from Brett’s free products of want to ensure the great services and tools that Bret has created you paid for keep improving go help him out.
Closing Delicious? Lessons to be Learned
There was a kerfuffle a couple weeks back around Delicious when the social bookmarking service Delicious was marked for end of life by Yahoo, which caused a rather large number I know to go rather nuts. Yahoo, has made the claim that they are not shutting the service down, which only seems like a stall tactic, but perhaps they may actually sell it (many accounts from former Yahoo and Delicious teams have pointed out the difficulties in that, as it was ported to Yahoo�s own services and with their own peculiarities).
Redundancy
Never the less, this brings-up an important point: Redundancy. One lesson I learned many years ago related to the web (heck, related to any thing digital) is it will fail at some point. Cloud based services are not immune and the network connection to those services is often even more problematic. But, one of the tenants of the Personal InfoCloud is it is where you keep your information across trusted services and devices so you have continual and easy access to that information. Part of ensuring that continual access is ensuring redundancy and backing up. Optimally the redundancy or back-up is a usable service that permits ease of continuing use if one resource is not reachable (those sunny days where there's not a cloud to be seen). Performing regular back-ups of your blog posts and other places you post information is valuable. Another option is a central aggregation point (these are long dreamt of and yet to be really implemented well, this is a long brewing interest with many potential resources and conversations).
With regard to Delicious I�ve used redundant services and manually or automatically fed them. I was doing this with Ma.gnol.ia as it was (in part) my redundant social bookmarking service, but I also really liked a lot of its features and functionality (there were great social interaction design elements that were deployed there that were quite brilliant and made the service a real gem). I also used Diigo for a short while, but too many things there drove me crazy and continually broke. A few months back I started using Pinboard, as the private reincarnation of Ma.gnol.ia shut down. I have also used ZooTool, which has more of a visual design community (the community that self-aggregates to a service is an important characteristic to take into account after the viability of the service).
Pinboard has been a real gem as it uses the commonly implemented Delicious API (version 1) as its core API, which means most tools and services built on top of Delicious can be relatively easily ported over with just a change to the URL for source. This was similar for Ma.gnol.ia and other services. But, Pinboard also will continually pull in Delicious postings, so works very well for redundancy sake.
There are some things I quite like about Pinboard (some things I don�t and will get to them) such as the easy integration from Instapaper (anything you star in Instapaper gets sucked into your Pinboard). Pinboard has a rather good mobile web interface (something I loved about Ma.gnol.ia too). Pinboard was started by co-founders of Delicious and so has solid depth of understanding. Pinboard is also a pay service (based on an incremental one time fee and full archive of pages bookmarked (saves a copy of pages), which is great for its longevity as it has some sort of business model (I don�t have faith in the �underpants - something - profit� model) and it works brilliantly for keeping out spammer (another pain point for me with Diigo).
My biggest nit with Pinboard is the space delimited tag terms, which means multi-word tag terms (San Francisco, recent discovery, etc.) are not possible (use of non-alphabetic word delimiters (like underscores, hyphens, and dots) are a really problematic for clarity, easy aggregation with out scripting to disambiguate and assemble relevant related terms, and lack of mainstream user understanding). The lack of easily seeing who is following my shared items, so to find others to potentially follow is something from Delicious I miss.
For now I am still feeding Delicious as my primary source, which is naturally pulled into Pinboard with no extra effort (as it should be with many things), but I'm already looking for a redundancy for Pinboard given the questionable state of Delicious.
The Value of Delicious
Another thing that surfaced with the Delicious end of life (non-official) announcement from Yahoo was the incredible value it has across the web. Not only do people use it and deeply rely on it for storing, contextualizing links/bookmarks with tags and annotations, refinding their own aggregation, and sharing this out easily for others, but use Delicious in a wide variety of different ways. People use Delicious to surface relevant information of interest related to their affinities or work needs, as it is easy to get a feed for not only a person, a tag, but also a person and tag pairing. The immediate responses that sounded serious alarm with news of Delicious demise were those that had built valuable services on top of Delicious. There were many stories about well known publications and services not only programmatically aggregating potentially relevant and tangential information for research in ad hoc and relatively real time, but also sharing out of links for others. Some use Delicious to easily build �related information� resources for their web publications and offerings. One example is emoted by Marshall Kirkpatrick of ReadWriteWeb wonderfully describing their reliance on Delicious
It was clear very quickly that Yahoo is sitting on a real backbone of many things on the web, not the toy product some in Yahoo management seemed to think it was. The value of Delicious to Yahoo seemingly diminished greatly after they themselves were no longer in the search marketplace. Silently confirmed hunches that Delicious was used as fodder to greatly influence search algorithms for highly potential synonyms and related web content that is stored by explicit interest (a much higher value than inferred interest) made Delicious a quite valued property while it ran its own search property.
For ease of finding me (should you wish) on Pinboard I am http://pinboard.in/u:vanderwal
----
Good relevant posts from others:
As If Had Read
The idea of a tag "As If Had Read" started as a riff off of riffs with David Weinberger at Reboot 2008 regarding the "to read" tag that is prevalent in many social bookmarking sites. But, the "as if had read" is not as tongue-in-cheek at the moment, but is a moment of ah ha!
I have been using DevonThink on my Mac for 5 or more years. It is a document, note, web page, and general content catch all that is easily searched. But, it also pulls out relevance to other items that it sees as relevant. The connections it makes are often quite impressive.
My Info Churning Patterns
I have promised for quite a few years that I would write-up how I work through my inbound content. This process changes a lot, but it is back to a settled state again (mostly). Going back 10 years or more I would go through my links page and check all of the links on it (it was 75 to 100 links at that point) to see if there was something new or of interest.
But, that changed to using a feedreader (I used and am back to using Net News Wire on Mac as it has the features I love and it is fast and I can skim 4x to 5x the content I can in Google Reader (interface and design matters)) to pull in 400 or more RSS feeds that I would triage. I would skim the new (bold) titles and skim the content in the reader, if it was of potential interest I open the link into a browser tab in the background and just churn through the skimming of the 1,000 to 1,400 new items each night. Then I would open the browser to read the tabs. At this stage I actually read the content and if part way through it I don't think it has current or future value I close the tab. But, in about 90 minutes I could triage through 1,200 to 1,400 new RSS feed items, get 30 to 70 potential items of value open in tabs in a browser, and get this down to a usual 5 to 12 items of current or future value. Yes, in 90 minutes (keeping focus to sort the out the chaff is essential). But, from this point I would blog or at least put these items into Delicious and/or Ma.gnolia or Yahoo MyWeb 2.0 (this service was insanely amazing and was years ahead of its time and I will write-up its value).
The volume and tools have changed over time. Today the same number of feeds (approximately 400) turn out 500 to 800 new items each day. I now post less to Delicious and opt for DevonThink for 25 to 40 items each day. I stopped using DevonThink (DT) and opted for Yojimbo and then Together.app as they had tagging and I could add my context (I found my own context had more value than DevonThink's contextual relevance engine). But, when DevonThink added tagging it became an optimal service and I added my archives from Together and now use DT a lot.
Relevance of As if Had Read
But, one of the things I have been finding is I can not only search within the content of items in DT, but I can quickly aggregate related items by tag (work projects, long writing projects, etc.). But, its incredible value is how it has changed my information triage and process. I am now taking those 30 to 40 tabs and doing a more in depth read, but only rarely reading the full content, unless it is current value is high or the content is compelling. I am acting on the content more quickly and putting it into DT. When I need to recall information I use the search to find content and then pull related content closer. I not only have the item I was seeking, but have other related content that adds depth and breath to a subject. My own personal recall of the content is enough to start a search that will find what I was seeking with relative ease. But, were I did a deeper skim read in the past I will now do a deeper read of the prime focus. My augmented recall with the brilliance of DevonThink works just as well as if I had read the content deeply the first time.
Return to the Blog and Life
Things have been quiet here? Um, yes they have. The past couple years have been full of changes and struggles. It seemed that just as things were turning from a rough stretch on personal and work front, something would rise up and cripple that forward progress.
This past year it was my dad calling in June of 2009 saying he cancer of the stomach that had spread to the liver. He seemed to improve quite a bit by Christmas of 2009 as he and my mom came back to visit, which was quite wonderful. But, on the return home he started not doing well and they found a tumor on his brain. Things stopped improving after this and it became a bit of a rough road for him. Not paying close attention to my own well being it really had an impact on me. He was my best buddy and I knew time was running short.
In July of this year my dad died and while it was really hard to comprehend and sad, it was also freeing. Not only did that concern and un-noticed energy focus had shifted, but I also had the focus that the safety net of parents love, guidance, and all types of parental support had sifted from a set of two, to just one. But, I realized I still had two feet and put that energy and time back into work.
Time Spent Digging
During the past couple years during all the change and struggle, I've spent a lot of time sorting through the things I am deeply passionate about, which are many and fit wonderfully with the work I do. I have spent a lot of time digging quite deeply into social software and the whys and how it works, but more intrigued where it doesn't with the 90% of the world that make up the mainstream. I have a lot of writing I haven't posted or shared on this, but have some of it in workshops and presentations I have done in the past couple years. That will likely be finally getting posted over at Personal InfoCloud.
Over many years and as part of my formal education I have read much of the usual corpus of social theorists, whom I always finding myself having to set aside reality to embrace the theorists models enough to understand them, but then come back to reality and they don't fit as well as a whole. I've always been mindful of them, but as I have been digging back into my older frameworks of the Model of Atraction and Come to Me Web and how they helped me work through and understand interactions with information on the web and beyond to build and frame next generation services, along with helping others do the same.
This review and digging has lead me to a lot of understandings and realizations around the social web and echos all the years of building, managing, iterating, and maintaining social tools. The same problems always surface, which are the tools don't really allow humans to be social like humans are social with out a mediated interface. But there are basic understanding of how humans are social through tools as mediated interfaces that is counter to many of the ways many of the tools and services are developed and provided.
Now mixing the older Model of Attraction and come to me web frameworks for thinking with the models and understandings I have come to in the past few years regarding social software have really gelled. These ideas will be getting out there and have been the fodder for client work that is resurfacing now that the economy has become out of its dire state (for now).
About that Book
As many know I was writing a book on folksonomy for O'Reilly. That book hit a wall (no, not a Vander Wal), or a few of them and I was notified O'Reilly would not be publishing it. Early in writing it I got stumped by many things that I was seeing as they did not fit any of the social models being touted as core to understanding social in the Web 2.0 sense. It took me about 18 months to deconstruct all of what I knew, what others knew, and get to models I could use to think through some of the really strong values people were finding and the problems that people were having that seems completely counter to "how the social web works&qout;.
Following this there were many changes happening in my personal life that took attention and focus. But, at the same time the services and tools were changing drastically. Many of the really good tools that were addressing the hard problems, but not popular were shutting down. This was also happening for the tools for organizations to purchase and use internally (where my main focus has been). But, content for the book is still moving forward and I am looking for a publisher that fits well for it. Now that SharePoint 2010 has social bookmarking / tagging in it (although a really really rough interface for it) the book has much more value, so people deploying it can have a much better understanding of what is really needed to have it help remove the huge problem organizations face, of not being able to find and refind information they are sure they have when they need it. But, I am also free to blog much of what was heading into the book so it can get feedback and more eyes honing it.
Back Blogging?
Yes! I am back blogging. More non-work type posts will be here at Off the Top and work related content is over at Personal InfoCloud, but also am dropping odd bits in my Tumblr vanderwal blog. I am likely going to change the platform under this blog to something that I did not write in 2001 sometime in the next couple of months (nearly 2,000 post and categories to transfer).
Social Design for the Enterprise Workshop in Washington, DC Area
I am finally bringing workshop to my home base, the Washington, DC area. I am putting on a my �Social Design for the Enterprise� half-day workshop on the afternoon of July 17th at Viget Labs (register from this prior link).
Yes, it is a Friday in the Summer in Washington, DC area. This is the filter to sort out who really wants to improve what they offer and how successful they want their products and solutions to be.
Past Attendees have Said...
�A few hours and a few hundred dollar saved us tens of thousands, if not well into six figures dollars of value through improving our understanding� (Global insurance company intranet director)
From an in-house workshop�
�We are only an hour in, can we stop? We need to get many more people here to hear this as we have been on the wrong path as an organization� (National consumer service provider)
�Can you let us know when you give this again as we need our [big consulting firm] here, they need to hear that this is the path and focus we need� (Fortune 100 company senior manager for collaboration platforms)
�In the last 15 minutes what you walked us through helped us understand a problem we have had for 2 years and a provided manner to think about it in a way we can finally move forward and solve it� (CEO social tool product company)
Is the Workshop Only for Designers?
No, the workshop is aimed at a broad audience. The focus of the workshop gets beyond the tools� features and functionality to provide understanding of the other elements that make a giant difference in adoption, use, and value derived by people using and the system owners.
The workshop is for user experience designers (information architects, interaction designers, social interaction designers, etc.), developers, product managers, buyers, implementers, and those with social tools running already running.
Not Only for Enterprise
This workshop with address problems for designing social tools for much better adoption in the enterprise (in-house use in business, government, & non-profit), but web facing social tools.
The Workshop will Address�
Designing for social comfort requires understanding how people interact in a non-mediated environment and what realities that we know from that understanding must we include in our design and development for use and adoption of our digital social tools if we want optimal adoption and use.
- Tools do not need to be constrained by accepting the 1-9-90 myth.
- Understanding the social build order and how to use that to identify gaps that need design solutions
- Social comfort as a key component
- Matrix of Perception to better understanding who the use types are and how deeply the use the tool so to build to their needs and delivering much greater value for them, which leads to improved use and adoption
- Using the for elements for enterprise social tool success (as well as web facing) to better understand where and how to focus understanding gaps and needs for improvement.
- Ways user experience design can be implemented to increase adoption, use, and value
- How social design needs are different from Web 2.0 and what Web 2.0 could improve with this understanding
More info...
For more information and registration to to Viget Lab's Social Design for the Enterprise page.
I look forward to seeing you there.
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id�67bb8b-4652-46bc-bc0d-996c1a2d5205)
Optimizing Tagging UI for People & Search
Overview/Intro
One of my areas of focus is around social tools in the workplace (enterprise 2.0) is social bookmarking. Sadly, is does not have the reach it should as it and wiki (most enterprise focused wikis have collective voice pages (blogs) included now & enterprise blog tools have collaborative document pages (wikis). I focus a lot of my attention these days on what happens inside the organization�s firewall, as that is where their is incredible untapped potential for these tools to make a huge difference.
One of the things I see on a regular basis is tagging interfaces on a wide variety of social tools, not just in social bookmarking. This is good, but also problematic as it leads to a need for a central tagging repository (more on this in a later piece). It is good as emergent and connective tag terms can be used to link items across tools and services, but that requires consistency and identity (identity is a must for tagging on any platform and it is left out of many tagging instances. This greatly decreases the value of tagging - this is also for another piece). There are differences across tools and services, which leads to problems of use and adoption within tools is tagging user interface (UI).
Multi-term Tag Intro
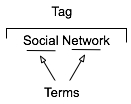 The multi-term tag is one of the more helpful elements in tagging as it provides the capability to use related terms. These multi-term tags provide depth to understanding when keeping the related tag terms together. But the interfaces for doing this are more complex and confusing than they should be for human, as well as machine consumption.
The multi-term tag is one of the more helpful elements in tagging as it provides the capability to use related terms. These multi-term tags provide depth to understanding when keeping the related tag terms together. But the interfaces for doing this are more complex and confusing than they should be for human, as well as machine consumption.
In the instance illustrated to the tag is comprised or two related terms: social and network. When the tool references the tag, it is looking at both parts as a tag set, which has a distinct meaning. The individual terms can be easily used for searches seeking either of those terms, but knowing the composition of the set, it is relatively easy for the service to offer up "social network" when a person seeks just social or network in a search query.
One common hindrance with social bookmarking adoption is those familiar with it and fans of it for enterprise use point to Delicious, which has a couple huge drawbacks. The compound multi-term tag or disconnected multi-term tags is a deep drawback for most regular potential users (the second is lack of privacy for shared group items). Delicious breaks a basic construct in user focussed design: Tools should embrace human methods of interaction and not humans embracing tech constraints. Delicious is quite popular with those of us malleable in our approach to adopt a technology where we adapt our approach, but that percentage of potential people using the tools is quite thin as a percentage of the population.. Testing this concept takes very little time to prove.
So, what are the options? Glad you asked. But, first a quick additional excursion into why this matters.
Conceptual Models Missing in Social Tool Adoption
One common hinderance for social tool adoption is most people intended to use the tools are missing the conceptual model for what these tools do, the value they offer, and how to personally benefit from these values. There are even change costs involved in moving from a tool that may not work for someone to something that has potential for drastically improved value. The "what it does", "what value it has", and "what situations" are high enough hurdles to cross, but they can be done with some ease by people who have deep knowledge of how to bridge these conceptual model gaps.
What the tools must not do is increase hurdles for adoption by introducing foreign conceptual models into the understanding process. The Delicious model of multi-term tagging adds a very large conceptual barrier for many & it become problematic for even considering adoption. Optimally, Delicious should not be used alone as a means to introduce social bookmarking or tagging.
We must remove the barriers to entry to these powerful offerings as much as we can as designers and developers. We know the value, we know the future, but we need to extend this. It must be done now, as later is too late and these tools will be written off as just as complex and cumbersome as their predecessors.
If you are a buyer of these tools and services, this is you guideline for the minimum of what you should accept. There is much you should not accept. On this front, you need to push back. It is your money you are spending on the products, implementation, and people helping encourage adoption. Not pushing back on what is not acceptable will greatly hinder adoption and increase the costs for more people to ease the change and adoption processes. Both of these costs should not be acceptable to you.
Multi-term Tag UI Options
Compound Terms
I am starting with what we know to be problematic for broad adoption for input. But, compound terms also create problems for search as well as click retrieval. There are two UI interaction patterns that happen with compound multi-term tags. The first is the terms are mashed together as a compound single word, as shown in this example from Delicious.
The problem here is the mashing the string of terms "architecture is politics" into one compound term "architectureispolitics". Outside of Germanic languages this is problematic and the compound term makes a quick scan of the terms by a person far more difficult. But it also complicates search as the terms need to be broken down to even have LIKE SQL search options work optimally. The biggest problem is for humans, as this is not natural in most language contexts. A look at misunderstood URLs makes the point easier to understand (Top Ten Worst URLs)
The second is an emergent model for compound multi-term tags is using a term delimiter. These delimiters are often underlines ( _ ), dots ( . ), or hyphens ( - ). A multi-term tag such as "enterprise search" becomes "enterprise.search", "enterprise_search" and "enterprise-search".
While these help visually they are less than optimal for reading. But, algorithmically this initially looks to be a simple solution, but it becomes more problematic. Some tools and services try to normalize the terms to identify similar and relevant items, which requires a little bit of work. The terms can be separated at their delimiters and used as properly separated terms, but since the systems are compound term centric more often than not the terms are compressed and have similar problems to the other approach.
Another reason this is problematic is term delimiters can often have semantic relevance for tribal differentiation. This first surface terms when talking to social computing researchers using Delicious a few years ago. They pointed out that social.network, social_network, and social-network had quite different communities using the tags and often did not agree on underlying foundations for what the term meant. The people in the various communities self identified and stuck to their tribes use of the term differentiated by delimiter.
The discovery that these variations were not fungible was an eye opener and quickly had me looking at other similar situations. I found this was not a one-off situation, but one with a fair amount of occurrence. When removing the delimiters between the terms the technologies removed the capability of understanding human variance and tribes. This method also breaks recommendation systems badly as well as hindering the capability of augmenting serendipity.
So how do these tribes identify without these markers? Often they use additional tags to identity. The social computing researchers add "social computing", marketing types add "marketing", etc. The tools then use their filtering by co-occurrence of tags to surface relevant information (yes, the ability to use co-occurrence is another tool essential). This additional tag addition help improve the service on the whole with disambiguation.
Disconnected Multi-term Tags
The use of distinct and disconnected term tags is often the intent for space delimited sites like Delicious, but the emergent approach of mashing terms together out of need surfaced. Delicious did not intend to create mashed terms or delimited terms, Joshua Schachter created a great tool and the community adapted it to their needs. Tagging services are not new, as they have been around for more than two decades already, but how they are built, used, and platforms are quite different now. The common web interface for tagging has been single terms as tags with many tags applied to an object. What made folksonomy different from previous tagging was the inclusion of identity and a collective (not collaborative) voice that intelligent semantics can be applied to.
The downside of disconnected terms in tagging is certainty of relevance between the terms, which leads to ambiguity. This discussion has been going on for more than a decade and builds upon semantic understanding in natural language processing. Did the tagger intend for a relationship between social & network or not. Tags out of the context of natural language constructs provide difficulties without some other construct for sense making around them. Additionally, the computational power needed to parse and pair potential relevant pairings is somethings that becomes prohibitive at scale.
Quoted Multi-term Tags
One of the methods that surfaced early in tagging interfaces was the quoted multi-term tags. This takes becomes #&039;research "social network" blog' so that the terms social network are bound together in the tool as one tag. The biggest problem is still on the human input side of things as this is yet again not a natural language construct. Systematically the downside is these break along single terms with quotes in many of the systems that have employed this method.
What begins with a simple helpful prompt...:
Still often can end up breaking as follows (from SlideShare):
Comma Delimited Tags
Non-space delimiters between tags allows for multi-term tags to exist and with relative ease. Well, that is relative ease for those writing Western European languages that commonly use commas as a string separator. This method allows the system to grasp there are multi-term tags and the humans can input the information in a format that may be natural for them. Using natural language constructs helps provide the ability ease of adoption. It also helps provide a solid base for building a synonym repository in and/or around the tagging tools.
While this is not optimal for all people because of variance in language constructs globally, it is a method that works well for a quasi-homogeneous population of people tagging. This also takes out much of the ambiguity computationally for information retrieval, which lowers computational resources needed for discernment.
Text Box Per Tag
Lastly, the option for input is the text box per tag. This allows for multi-term tags in one text box. Using the tab button on the keyboard after entering a tag the person using this interface will jump down to the next empty text box and have the ability to input a term. I first started seeing this a few years ago in tagging interfaces tools developed in Central Europe and Asia. The Yahoo! Bookmarks 2 UI adopted this in a slightly different implementation than I had seen before, but works much the same (it is shown here).
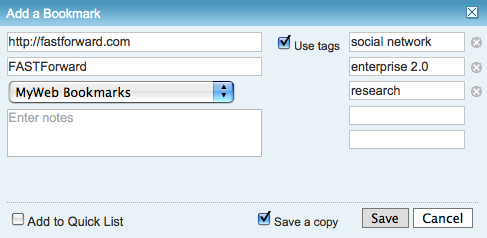
There are many variations of this type of interface surfacing and are having rather good adoption rates with people unfamiliar to tagging. This approach tied to facets has been deployed in Knowledge Plaza by Whatever s/a and works wonderfully.
All of the benefits of comma delimited multi-term tag interfaces apply, but with the added benefit of having this interface work internationally. International usage not only helps build synonym resources but eases language translation as well, which is particularly helpful for capturing international variance on business or emergent terms.
Summary
This content has come from more than four years of research and discussions with people using tools, both inside enterprise and using consumer web tools. As enterprise moves more quickly toward more cost effective tools for capturing and connecting information, they are aware of not only the value of social tools, but tools that get out the way and allow humans to capture, share, and interact in a manner that is as natural as possible with the tools getting smart, not humans having to adopt technology patterns.
This is a syndicated version of the same post at Optimizing Tagging UI for People & Search :: Personal InfoCloud that has moderated comments available.
"Building the social web" Full-day Workshop in Copenhagen on June 30th
Through the wonderful cosponsoring of FatDUX I am going to be putting on a full-day workshop Building the Social Web on June 30th in Copenhagen, Denmark (the event is actually in Osterbro). This is the Monday following Reboot, where I will be presenting.
I am excited about the workshop as it will be including much of my work from the past nine months on setting social foundations for successful services, both on the web and inside organizations on the intranet. The workshop will help those who are considering, planning, or already working on social sites to improve the success of the services by providing frameworks that help evaluating and guiding the social interactions on the services.
Space is limited for this workshop to 15 seats and after its announcement yesterday there are only 10 seats left as of this moment.
Speaking at the International Forum on Enterprise 2.0 Near Milan, Italy
Under a month from now I have the wonderful pleasure of speaking at the International Forum on Enterprise 2.0, this is just outside of Milan in Varese, Italy on June 25, 2008. I am really looking forward to this event as there are many people whom I chat with on Skype with and chat with in other ways about enterprise and the use of social tools inside these organizations. It is a wonderful opportunity to meet them in person and to listen to them live as they present. Already I know many people attending the event from the United Kingdom, Switzerland, Germany, Austria, Spain, and (of course) Italy. If you are in Europe and have interest this should be a great event to get a good overview and talk with others with interest and experience. Oh, did I mention the conference is FREE?
I will be presenting an overview on social bookmarking and folksonomy and the values that come out of these tools, but also the understanding needed to make good early decisions about the way forward.
I look forward to meeting those of you who attend.
Enterprise 2.0 Boston - After Noah: What to do After the Flood (of Information)
I am looking forward to being at the Enterprise 2.0 Conference in Boston from June 10 to June 12, 2008. I am going to be presenting on June 10, 2008 at 1pm on After Noah: Making Sense of the Flood (of Information). This presentation looks at what to expect with social bookmarking tools inside an organization as they scale and mature. It also looks at how to manage the growth as well as encourage the growth.
Last year at the same Enterprise 2.0 conference I presented on Bottom-up Tagging (the presentation is found at Slideshare, Bottom-up All the Way Down: How Tags Help Businesses Organize, which has had over 8,800 viewing on Slideshare), which was more of a foundation presentation, but many in the audience were already running social bookmarking services in-house or trying them in some manner. This year my presentation is for those with an understanding of what social bookmarking and folksonomy are and are looking for what to expect and how to manage what is happening or will be coming along. I will be covering how to manage heavy growth as well as how to increase adoption so there is heavy usage to manage.
I look forward to seeing you there. Please say hello, if you get a chance.