Off the Top: Web apps Entries
Showing posts: 1-15 of 200 total posts
New Adoption Points
One of those things where, yet again, realize you have a really quick personal adoption threshold when a new device fills in and you start wondering why everything can’t be logged into with a fingerprint. Then there is the, “why are you calling me on my payment device?”
It has been over 30 years of having new devices arrive at semi-regular pace and quickly disrupting things for workflows around devices and interactions, which is followed often by relatively quick adoption and getting used to a new mental model that makes things a little easier. This is really true for software that is buggy and never really fixed and where I (as well as other humans are the human affordance system).
The Software Counter Model to Quick Change Adoption
As much as new physical hardware and software interaction model shifts largely causes little difficulty with changing for more ease of use, the counter to this with software with a lot of human need for grasping mental models. It is particularly difficult when structuring mental models and organization structure before using software is something required.
There have been some good discounts on Tinderbox across podcasts I listen to or websites around Mac productivity I read, so I nabbed a copy. I have had long discussion around Tinderbox for over a decade and it has been on my want list for large writing and research projects. I have had quite a few friends who have been long time users (longer than I have been a DevonThink user), but I don’t seem to have one in my current circle of colleagues (I you are one and would love to chat, please reach out).
I have a few projects that I think would make great sense to put into Tinderbox, but not really grokking the structure and mental model and flows - particularly around what I wish I would know when I have a lot of content in it. It is feeling a lot like trying to read Japanese and not having learned the characters. I also wish I had kept better notes a few years back when I was deeply sold on a need for Tinderbox, but didn’t capture a detailed why and how I thought it would work into workflow.
Some Tools are Nearly There as a Continual State
I have some software and services that I use a fair amount with hope that they will get much much better with a few relatively small things. Evernote is nearly always in this category. Evernote is a good product, but never gets beyond just good. The search always falls apart at scale (it was around 2,000 objects and had about doubled that scaling threshold pain point) and I can’t sort out how to script things easily or remotely drop content into the correct notebook from email or other easy entry model. There are a lot of things I wish Evernote would become with a few minor tweaks to support a scalable solid no (or very few faults tool), but it never quite takes those steps.
Their business tool offering is good for a few use cases, which are basic, but getting some smart and intelligence uses with better search (search always seems to be a pain point and something that DevonThink has nailed for 10 years) would go a really long way. Evernote’s Context is getting closer, but is lacking up front fuzzy, synonym, and narrowing search with options (either the “did you mean” or narrowing / disambiguation hints / helps).
We will get there some day, but I just wish the quick adoption changes with simple hardware interaction design and OS changes would become as normal as quickly with new other knowledge and information tools for personal use (always better than) or business.
Changing Hosts and Server Locations
I’ve been in the midst of thinking through a web host / server move for vanderwal.net for a while. I started running a personal site in 1995 and was running it under vanderwal.net since 1997. During this time it has gone through six of 7 different hosts. The blog has been on three different hosts and on the same host since January 2006.
I’ve been wanting better email hosting, I want SSH access back, more current updates to: OS; scripting for PHP, Ruby, and Python; MySQL; and other smaller elements. A lot has changed in the last two to three years in web and server hosting.
The current shift is the 4th generation that started with simple web page hosting with limited scripting options, but often had some SSH and command line access to run cron jobs. The second was usually had a few scripting options and database to run light CMS or other dynamic pages, but the hosting didn’t give you access to anything below the web directory (problematic when trying to set your credentials for login out of the web directory, running more than one version of a site (dev, production, etc.), and essential includes that for security are best left out of the web directory). The second generation we often lost SSH and command line as those coming in lacked skills to work at the command line and could cripple a server with ease with a minor accident. The third has been more robust hosting with proper web directory set up and access to sub directories, having multiple scripting resources, having SSH and command line back (usually after proven competence), having control of setting up your own databases at will, setting up your own subdomains at will, and more. The third generation was often still hosting many sites on one server and a run away script or site getting hammered with traffic impacted the whole server. These hosts also often didn’t have the RAM to run current generations of tools (such as Drupal which can be a resource hog if not using command line tools like drush that thankfully made Drupal easier to configure in tight constraints from 2006 forward).
Today’s Options
Today we have a fourth generation of web host that replicates upgraded services like your own private server or virtual private server, but at lighter web hosting prices. I’ve been watching Digital Ocean for a few months and a couple months back I figured for $5 per month it was worth giving it a shot for some experiments and quick modeling of ideas. Digital Ocean starts with 512 MB or RAM, 20GB of SSD space (yes, your read that right, SSD hard drive), and 1TB of transfer. The setup is essentially a virtual private server, which makes experimentation easier and safer (if you mess up you only kill your own work not the work of others - to fix it wipe and rebuild quickly if it is that bad). Digital Ocean also lets you setup your server as you wish in about a minute of creation time with OS, scripting, and database options there for your choosing.
In recently Marco Arment has written up the lay of the land for hosting options from his perspective, which is a great overview. I’ve also been following Phil Gyford’s change of web hosting and like Phil I am dealing with a few domains and projects. I began looking at WebFaction and am liking what is there too. WebFaction adds in email into the equation and 100GB of storage on RAID 10 storage. Like Digital Ocean it has full shell scripting and a wide array of tools to select from to add to your server. This likely would be a good replacement for my core web existence here at vanderwal.net and its related services. WebFaction provides some good management interfaces and smoothing some of the rough edges.
There are two big considerations in all of this: 1) Email; 2) Server location.
Email is a huge pain point for me. It should be relatively bullet proof (as it was years ago). To get bullet proof email the options boil down to going to a dedicated mail service like exchange or something like FastMail, a hosted Exchange server, or Google Apps. Having to pester the mail host to kick a server isn’t really acceptable and that has been a big reason I am considering moving my hosting. Also sitting on servers that get their IP address in blocks of blacklisted email servers (or potentially blacklisted) makes things really painful as well. I have ruled out Exchange as an option due to cost, many open scripts I rely on don’t play well with Exchange, and the price related to having someone maintain it.
Google Apps is an option, but my needs for all the other pieces that Google Apps offers aren’t requirements. I am looking at about 10 email addresses with one massive account in that set along with 2 or 3 other domains with one or two email accounts that are left open to catch the stray emails that drift in to those (often highly important). The cost of Google for this adds up quickly, even with using of aliases. I think having one of my light traffic domains on Google Apps would be good, the price of that and access to Google Apps to have access to for experimentation (Google Apps always arise in business conversations as a reference).
FastMail pricing is yearly and I know a lot of people who have been using it for years and rave about it. Having my one heavy traffic email there, as well as tucking the smaller accounts with lower traffic hosted there would be a great setup. Keeping email separate from hosting give uptime as well. FastMail is also testing calendar hosting with CalDAV, which is really interesting as well (I ran a CalDAV server for a while and it was really helpful and rather easy to manage, but like all things calendar it comes with goofy headaches, often related timezone and that bloody day light savings time, that I prefer others to deal with).
Last option is bundled email with web hosting. This has long been my experience. This is mostly a good solution, but rarely great. Dealing with many domains and multitudes of accounts email bundled with web hosting is a decent option. Mail hosting is rarely a deep strength of a web hosting company and often it is these providers that you have to pester to kick the mail server to get your mail flowing again (not only my experience, but darned near everybody I know has this problem and it should never work this way). I am wondering with the benefits of relatively inexpensive mail hosting bundled into web hosting is worth the pain.
I am likely to split my mail hosting across different solutions (the multiple web hosts and email hosts would still be less than my relatively low all in one web hosting I currently have).
Server Location
I have had web hosting in the US, UK, and now Australia and at a high level, I really don’t care where the the servers are located as the internet is mostly fast and self healing, so location and performance is a negligible distance for me (working with live shell scripting to a point that is nearly at the opposite side of the globe is rather mind blowing in how instantaneous this internet is).
My considerations related to where in the globe the servers are hosted comes down to local law (or lack of laws that are enforced). Sites sitting on European hosts require cookie notifications. The pull down / take down laws in countries are rather different. As a person with USA citizenship paperwork and hosting elsewhere, the laws that apply and how get goofy. The revelations of USA spying on its own people and servers has me not so keen to host in the US again, not that I ever have had anything that has come close to running afoul of laws or could ever be misconstrued as something that should draw attention. I have no idea what the laws are in Australia, which has been a bit of a concern for a while, but the host also has had servers in the US as well.
My options seem to be US, Singapore, UK, Netherlands, and Nordic based hosting. Nearly all the hosting options for web, applications, and mail provide options for location (the non-US options have grown like wildfire in the post Edward Snowden era). Location isn’t a deciding point, but it is something I will think through. I chose Australia as the host had great highly recommended hosting that has lived up to that for that generation of hosting options. It didn’t matter where the server was hosted eight years ago as the laws and implications were rather flat. Today the laws and implications are far less flat, so it will require some thinking through.
Non-UNIX Timestamping has Me Stamping in Frustration
In the slow process of updating things here on this site I have nearly finished with the restructuring the HTML (exception is the about page, which everytime I start on it the changes I start to make lead quickly to a bigger redesign).
Taking a break from the last HTML page restructuring I was looking at finally getting to correctly timestamping and listing the post times based on blog posting location. Everything after the 1783rd blog post currently picks up the server time stamp and that server is sitting in Eastern Australia, so everything (other than blog posts from Sydney) are not correctly timestamped. Most things are 14 to 15 hours ahead of when they were posted - yes, posted from the future.
Looking at my MySQL tables I didn’t use a Unix timestamp, but a SQL datetime as the core date stored and then split the date and time into separate varables created with parsing timestamp in PHP. This leaves 3 columns to convert. It is a few scripts to write, but not bad, but just a bit of a pain. Also in this change is setting up time conversions that are built into the post location, but shifts in time for day light savings starts adding pain that I don’t want to introduce. I’ve been considering posting in GMT / UTC and on client side showing the posting time with relative user local time with a little JavaScript.
I would like to do this before a server / host move I’ve been considering. At this point I may set up a move and just keep track of the first post on the new server, then at some point correct the time for the roughly 500 posts while the server was in Eastern Australia.
Brett Terpstra Focusses on His Work Full-time
I have been a fan of Brett Terpstra for some time. I found his site through a few buds who focus on productivity and personal workflows (including scripting). I have followed his Systematic podcast since the first episode and have found it is the one podcast I listen to when my weekly listening dwindles to just one podcast. His nvALT became an app that is always running and where a lot of writing snippets get stored on my Mac (that content I also reach on my iOS devices to edit and extend). His Marked2 app not only is my Markedown viewer, but a rather good writing analysis tool.
Not only all of this but Brett is a tagger and not only tags, belives tagging is helpful for personal filtering and workflow, but has built tools to greater extend tagging in and around Mac and iOS. If you talk folksonomy and pull the third leg of it, person / identity back into just your own perspective and keep the tag and objects in place you have the realm that Brett focusses and pushes farther for our own personal benefit.
Brett Steps Out to Focus on His Work
This week I have been incredibly happy to learn that Brett moved out of his daytime job to and his new job is to focus on his products, podcast, writing, and new projects and products. This is great news for all of us. Brett took this step before, but we can help him keep these tools and services flowing by supporting him.
If you have benefitted from Brett’s free products of want to ensure the great services and tools that Bret has created you paid for keep improving go help him out.
HTML5 Demo Watch
Thanks to the Berg Friday Links I found the Suit up or Die Magazine and Cut the Rope HTML5 demo sites.
Both have me thinking this is really close, then I remember one of my favorite periodical apps, Financial Times went HTML5 more than a year ago. FT went HTML5 to better manage the multi-platform development process needed for iOS and the multitude of Android versions. While many have said the development is roughly 1.5x what it would take for just one platform development it does same incredible amount of time building an app across all platforms. Since all the major smart phone platforms have their native browsers built on webkit, there is some smart thinking in that approach.
Personally, my big niggle with the FT app is while it is browser based doesn’t have Instapaper built-in and it moves me out of the app to send a link of an article (often to myself because lacking Instapaper) rather than natively in the app, or exposing browser chrome so that I can do that while still remaining in the app and in reading their content mode. It would be really smart for FT to sort this out and fix these as it would keep me in the site and service reading, which I am sure they would love. If they could treat both of those like they do with Twitter and Facebook sharing out all within the app it would be brilliant.
The Data Journalism Handbook is Available
The Data Journalism Handbook is finally available online and soon as the book Data Journalism Handbook - from Amazon or The Data Journalism Handbook - from O’Reilly, which is quite exciting. Why you ask?
In the October of 2010 the Guardian in the UK posted a Data Journalism How To Guide that was fantastic. This was a great resource not only for data journalists, but for anybody who has interest in finding, gathering, assessing, and doing something with the data that is shared found in the world around us. These skill are not the sort of thing that many of us grew up with nor learned in school, nor are taught in most schools today (that is another giant problem). This tutorial taught me a few things that have been of great benefit and filled in gaps I had in my tool bag that was still mostly rusty and built using the tool set I picked up in the mid-90s in grad school in public policy analysis.
In the Fall of 2011 at MozFest in London many data journalist and others of like mind got together to share their knowledge. Out of this gathering was the realization and starting point for the handbook. Journalists are not typically those who have the deep data skills, but if they can learn (not a huge mound to climb) and have it made sensible and relatively easy in bite sized chunk the journalists will be better off.
All of us can benefit from this book in our own hands. Getting to the basics of how gather and think through data and the questions around it, all the way through how to graphically display that data is incredibly beneficial. I know many people who have contributed to this Handbook and think the world of their contributions. Skimming through the version that is one the web I can quickly see this is going to be an essential reference for all, not just journalists, nor bloggers, but for everybody. This could and likely should be the book used in classes in high schools and university information essentials taught first semester first year.
Traits of Blogs with Highly Valued Content for Me
I was going through my inbound feeds of blogs, news, and articles and catching up on the week. In doing so I open things that are of potential interest in an external browser (as mentioned before in As if Had Read) and realized most have some common traits. Most don't have Twitter feed (most Twitter feeds run at a vastly different information velocity and with very different content areas that distract from the content at hand). As well, many do not have comments on them any more or have moderated comments using built-in commenting service/tool (very rarely is Disqus used).
Strong Content is the Draw
The thing in common is all are focused on the that blog post's content. The content and the focus on the idea at hand is the strength of the attraction.
Some of the blogs are back to their old ways of posting short ideas and things that flow through their lives the want to hold on to, but as also comfortable enough to share out for other's with similar interest.
Ancillary Content Can Easily Distract Attention and Value
Sorting out what the focus of a blog (personal or professional) is essential. The focus is the content and the main pieces on the page. It is good to help keep the focus there without any swirling tag cloud (these seem to be the brunt of the fun poking sticks at conferences these days as they add no value and are completely and utterly unusable, so much so those with the mike continually question what understanding somebody has to add them to their page or site) or any other moving updating object. When talking with readers most say they do not notice these objects, just like web ads have taught us to ignore their blinking and flashing and twirling. As is often said personal sites begin to look like entries in a NASCAR race, where the most anticipated outcomes are the wrecks.
I have seen many attempts at personal homepages and personal aggregation pages, which are of big interest to me (for personal archiving, searching, and review), which are a better place for pulling together the Twitter feed, Flickr, Instagram, Tumblr, etc. Aggregation of this content in a feed option is good too, but keeping the blog page content to a main focus on content is good for the reader and attention on the written word.
Yes, over on the right I have my social bookmarked links. It has been my intention to pull recent items with tags related to content tags, but that has yet to happen.
Closing Delicious? Lessons to be Learned
There was a kerfuffle a couple weeks back around Delicious when the social bookmarking service Delicious was marked for end of life by Yahoo, which caused a rather large number I know to go rather nuts. Yahoo, has made the claim that they are not shutting the service down, which only seems like a stall tactic, but perhaps they may actually sell it (many accounts from former Yahoo and Delicious teams have pointed out the difficulties in that, as it was ported to Yahoo�s own services and with their own peculiarities).
Redundancy
Never the less, this brings-up an important point: Redundancy. One lesson I learned many years ago related to the web (heck, related to any thing digital) is it will fail at some point. Cloud based services are not immune and the network connection to those services is often even more problematic. But, one of the tenants of the Personal InfoCloud is it is where you keep your information across trusted services and devices so you have continual and easy access to that information. Part of ensuring that continual access is ensuring redundancy and backing up. Optimally the redundancy or back-up is a usable service that permits ease of continuing use if one resource is not reachable (those sunny days where there's not a cloud to be seen). Performing regular back-ups of your blog posts and other places you post information is valuable. Another option is a central aggregation point (these are long dreamt of and yet to be really implemented well, this is a long brewing interest with many potential resources and conversations).
With regard to Delicious I�ve used redundant services and manually or automatically fed them. I was doing this with Ma.gnol.ia as it was (in part) my redundant social bookmarking service, but I also really liked a lot of its features and functionality (there were great social interaction design elements that were deployed there that were quite brilliant and made the service a real gem). I also used Diigo for a short while, but too many things there drove me crazy and continually broke. A few months back I started using Pinboard, as the private reincarnation of Ma.gnol.ia shut down. I have also used ZooTool, which has more of a visual design community (the community that self-aggregates to a service is an important characteristic to take into account after the viability of the service).
Pinboard has been a real gem as it uses the commonly implemented Delicious API (version 1) as its core API, which means most tools and services built on top of Delicious can be relatively easily ported over with just a change to the URL for source. This was similar for Ma.gnol.ia and other services. But, Pinboard also will continually pull in Delicious postings, so works very well for redundancy sake.
There are some things I quite like about Pinboard (some things I don�t and will get to them) such as the easy integration from Instapaper (anything you star in Instapaper gets sucked into your Pinboard). Pinboard has a rather good mobile web interface (something I loved about Ma.gnol.ia too). Pinboard was started by co-founders of Delicious and so has solid depth of understanding. Pinboard is also a pay service (based on an incremental one time fee and full archive of pages bookmarked (saves a copy of pages), which is great for its longevity as it has some sort of business model (I don�t have faith in the �underpants - something - profit� model) and it works brilliantly for keeping out spammer (another pain point for me with Diigo).
My biggest nit with Pinboard is the space delimited tag terms, which means multi-word tag terms (San Francisco, recent discovery, etc.) are not possible (use of non-alphabetic word delimiters (like underscores, hyphens, and dots) are a really problematic for clarity, easy aggregation with out scripting to disambiguate and assemble relevant related terms, and lack of mainstream user understanding). The lack of easily seeing who is following my shared items, so to find others to potentially follow is something from Delicious I miss.
For now I am still feeding Delicious as my primary source, which is naturally pulled into Pinboard with no extra effort (as it should be with many things), but I'm already looking for a redundancy for Pinboard given the questionable state of Delicious.
The Value of Delicious
Another thing that surfaced with the Delicious end of life (non-official) announcement from Yahoo was the incredible value it has across the web. Not only do people use it and deeply rely on it for storing, contextualizing links/bookmarks with tags and annotations, refinding their own aggregation, and sharing this out easily for others, but use Delicious in a wide variety of different ways. People use Delicious to surface relevant information of interest related to their affinities or work needs, as it is easy to get a feed for not only a person, a tag, but also a person and tag pairing. The immediate responses that sounded serious alarm with news of Delicious demise were those that had built valuable services on top of Delicious. There were many stories about well known publications and services not only programmatically aggregating potentially relevant and tangential information for research in ad hoc and relatively real time, but also sharing out of links for others. Some use Delicious to easily build �related information� resources for their web publications and offerings. One example is emoted by Marshall Kirkpatrick of ReadWriteWeb wonderfully describing their reliance on Delicious
It was clear very quickly that Yahoo is sitting on a real backbone of many things on the web, not the toy product some in Yahoo management seemed to think it was. The value of Delicious to Yahoo seemingly diminished greatly after they themselves were no longer in the search marketplace. Silently confirmed hunches that Delicious was used as fodder to greatly influence search algorithms for highly potential synonyms and related web content that is stored by explicit interest (a much higher value than inferred interest) made Delicious a quite valued property while it ran its own search property.
For ease of finding me (should you wish) on Pinboard I am http://pinboard.in/u:vanderwal
----
Good relevant posts from others:
Nokia to Nip Its Ecosystem?
First off, I admit it I like Nokia and their phones (it may be a bit more than like, actually). But, today's news regarding Nokia further refines development strategy to unify environments for Symbian and MeeGo is troubling, really troubling. Nokia is stating they are moving toward more of an app platform than software. It is a slight nuance in terms, but the app route is building light applications on a platform and not having access to underlying functionality, while software gets to dig deeper and put hooks deeper in the foundations to do what it needs. Simon Judge frames it well in his The End of Symbian for 3rd Party Development.
Killing A Valued Part of the Ecosystem
My love for Nokia is one part of great phone (voice quality is normally great, solidly built, etc.) and the other part is the software third party developers make. Nokia has had a wonderfully open platform for developers to make great software and do inventive things. Many of the cool new things iPhone developers did were done years prior for Nokia phones because it was open and hackable. For a while there was a python kit you could load to hack data and internal phone data, so to build service you wanted. This is nice and good, but my love runs deeper.
When my last Nokia (E61i) died after a few years, its replacement was a Nokia E72. I could have gone to iPhone (I find too many things that really bug me about iPhone to do that and it is still behind functionality I really like in the Nokia). But, the big thing that had me hooked on Nokia were two pieces of 3rd party software. An email application called ProfiMail and a Twitter client called Gravity. Both of these pieces of software are hands down my favorites on any mobile platform (BTW, I loathe the dumbed down Apple mail on iPhone/iPod Touch). But, I also get to use my favorite mobile browser Opera Mobile (in most cases I prefer Opera over Safari on iPhone platform as well). This platform and ecosystem, created the perfect fit for my needs.
Nearly every Nokia user I know (they are hard to find in the US, but most I know are in Europe) all have the same story. It is their favorite 3rd party applications that keep them coming back. Nearly everybody I know loves Gravity and hasn't found another Twitter client they would switch to on any other mobile platform. The Nokia offerings for email and browser are good, but the option to use that best meets your needs is brilliant and always has been, just as the unlocked phone choice rather than a carrier's mangled and crippled offering. If Nokia pulls my ability to choose, then I may choose a phone that doesn't.
Understanding Ecosystems is Important
Many people have trashed Nokia for not having a strong App Store like Apple does for iPhone. Every time I hear this I realize not only do people not understand the smartphone market that has existed for eight years or more prior to iPhone entering the market, but they do not grasp ecosystems. Apple did a smart thing with the App Store for iPhone and it solved a large problem, quality of applications and secondarily created a central place customers could find everything (this really no longer works well as the store doesn't work well at all with the scale it has reached).
While Apple's ecosystem works well, most other mobile platforms had a more distributed ecosystem, where 3rd party developers could build the applications and software, sell it directly from their site or put it in one or many of the mobile application/software stores, like Handango. This ecosystem is distributed hoards of people have been using it and the many applications offered up. When Nokia opened Ovi, which includes an app store with many offerings, many complained it didn't grow and have the mass of applications Apple did. Many applications that are popular for Nokia still are not in Ovi, because a prior ecosystem existed and still exists. That prior ecosystem is central what has made Nokia a solid option.
Most US mobile pundits only started paying attention to mobile when the iPhone arrived. The US has been very very late to the mobile game as a whole and equally good, if not better options for how things are done beyond Apple exist and have existed. I am really hoping this is not the end of one of those much better options (at least for me and many I know).
Social Design for the Enterprise Workshop in Washington, DC Area
I am finally bringing workshop to my home base, the Washington, DC area. I am putting on a my �Social Design for the Enterprise� half-day workshop on the afternoon of July 17th at Viget Labs (register from this prior link).
Yes, it is a Friday in the Summer in Washington, DC area. This is the filter to sort out who really wants to improve what they offer and how successful they want their products and solutions to be.
Past Attendees have Said...
�A few hours and a few hundred dollar saved us tens of thousands, if not well into six figures dollars of value through improving our understanding� (Global insurance company intranet director)
From an in-house workshop�
�We are only an hour in, can we stop? We need to get many more people here to hear this as we have been on the wrong path as an organization� (National consumer service provider)
�Can you let us know when you give this again as we need our [big consulting firm] here, they need to hear that this is the path and focus we need� (Fortune 100 company senior manager for collaboration platforms)
�In the last 15 minutes what you walked us through helped us understand a problem we have had for 2 years and a provided manner to think about it in a way we can finally move forward and solve it� (CEO social tool product company)
Is the Workshop Only for Designers?
No, the workshop is aimed at a broad audience. The focus of the workshop gets beyond the tools� features and functionality to provide understanding of the other elements that make a giant difference in adoption, use, and value derived by people using and the system owners.
The workshop is for user experience designers (information architects, interaction designers, social interaction designers, etc.), developers, product managers, buyers, implementers, and those with social tools running already running.
Not Only for Enterprise
This workshop with address problems for designing social tools for much better adoption in the enterprise (in-house use in business, government, & non-profit), but web facing social tools.
The Workshop will Address�
Designing for social comfort requires understanding how people interact in a non-mediated environment and what realities that we know from that understanding must we include in our design and development for use and adoption of our digital social tools if we want optimal adoption and use.
- Tools do not need to be constrained by accepting the 1-9-90 myth.
- Understanding the social build order and how to use that to identify gaps that need design solutions
- Social comfort as a key component
- Matrix of Perception to better understanding who the use types are and how deeply the use the tool so to build to their needs and delivering much greater value for them, which leads to improved use and adoption
- Using the for elements for enterprise social tool success (as well as web facing) to better understand where and how to focus understanding gaps and needs for improvement.
- Ways user experience design can be implemented to increase adoption, use, and value
- How social design needs are different from Web 2.0 and what Web 2.0 could improve with this understanding
More info...
For more information and registration to to Viget Lab's Social Design for the Enterprise page.
I look forward to seeing you there.
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id�67bb8b-4652-46bc-bc0d-996c1a2d5205)
Catching Up On Personal InfoCloud Blog Posts
Things here are a little quiet as I have been in writing mode as well as pitching new work. I have been blogging work related items over at Personal InfoCloud, but I am likely only going to be posting summaries of those pieces here from now on, rather than the full posts. I am doing this to concentrate work related posts, particularly on a platform that has commenting available. I am still running my own blogging tool here at vanderwal.net I wrote in 2001 and turned off the comments in 2006 after growing tired of dealing comment spam.
The following are recently posted over at Personal InfoCloud
SharePoint 2007: Gateway Drug to Enterprise Social Tools
SharePoint 2007: Gateway Drug to Enterprise Social Tools focusses on the myriad of discussions I have had with clients of mine, potential clients, and others from organizations sharing their views and frustrations with Microsoft SharePoint as a means to bring solid social software into the workplace. This post has been brewing for about two years and is now finally posted.
Optimizing Tagging UI for People & Search
Optimizing Tagging UI for People and Search focuses on the lessons learned and usability research myself and others have done on the various input interfaces for tagging, particularly tagging with using multi-term tags (tags with more than one word). The popular tools have inhibited adoption of tagging with poor tagging interaction design and poor patterns for humans entering tags that make sense to themselves as humans.
LinkedIn: Social Interaction Design Lessons Learned (not to follow)
I have a two part post on LinkedIn's social interaction design. LinkedIn: Social Interaction Design Lessons Learned (not to follow) - 1 of 2 looks at what LinkedIn has done well in the past and had built on top. Many people have expressed the new social interactions on LinkedIn have decreased the value of the service for them.
The second part, LinkedIn: Social Interaction Design Lessons Learned (not to follow) - 2 of 2 looks at the social interaction that has been added to LinkedIn in the last 18 months or so and what lessons have we as users of the service who pay attention to social interaction design have learned. This piece also list ways forward from what is in place currently.
Optimizing Tagging UI for People & Search
Overview/Intro
One of my areas of focus is around social tools in the workplace (enterprise 2.0) is social bookmarking. Sadly, is does not have the reach it should as it and wiki (most enterprise focused wikis have collective voice pages (blogs) included now & enterprise blog tools have collaborative document pages (wikis). I focus a lot of my attention these days on what happens inside the organization�s firewall, as that is where their is incredible untapped potential for these tools to make a huge difference.
One of the things I see on a regular basis is tagging interfaces on a wide variety of social tools, not just in social bookmarking. This is good, but also problematic as it leads to a need for a central tagging repository (more on this in a later piece). It is good as emergent and connective tag terms can be used to link items across tools and services, but that requires consistency and identity (identity is a must for tagging on any platform and it is left out of many tagging instances. This greatly decreases the value of tagging - this is also for another piece). There are differences across tools and services, which leads to problems of use and adoption within tools is tagging user interface (UI).
Multi-term Tag Intro
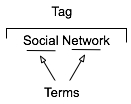 The multi-term tag is one of the more helpful elements in tagging as it provides the capability to use related terms. These multi-term tags provide depth to understanding when keeping the related tag terms together. But the interfaces for doing this are more complex and confusing than they should be for human, as well as machine consumption.
The multi-term tag is one of the more helpful elements in tagging as it provides the capability to use related terms. These multi-term tags provide depth to understanding when keeping the related tag terms together. But the interfaces for doing this are more complex and confusing than they should be for human, as well as machine consumption.
In the instance illustrated to the tag is comprised or two related terms: social and network. When the tool references the tag, it is looking at both parts as a tag set, which has a distinct meaning. The individual terms can be easily used for searches seeking either of those terms, but knowing the composition of the set, it is relatively easy for the service to offer up "social network" when a person seeks just social or network in a search query.
One common hindrance with social bookmarking adoption is those familiar with it and fans of it for enterprise use point to Delicious, which has a couple huge drawbacks. The compound multi-term tag or disconnected multi-term tags is a deep drawback for most regular potential users (the second is lack of privacy for shared group items). Delicious breaks a basic construct in user focussed design: Tools should embrace human methods of interaction and not humans embracing tech constraints. Delicious is quite popular with those of us malleable in our approach to adopt a technology where we adapt our approach, but that percentage of potential people using the tools is quite thin as a percentage of the population.. Testing this concept takes very little time to prove.
So, what are the options? Glad you asked. But, first a quick additional excursion into why this matters.
Conceptual Models Missing in Social Tool Adoption
One common hinderance for social tool adoption is most people intended to use the tools are missing the conceptual model for what these tools do, the value they offer, and how to personally benefit from these values. There are even change costs involved in moving from a tool that may not work for someone to something that has potential for drastically improved value. The "what it does", "what value it has", and "what situations" are high enough hurdles to cross, but they can be done with some ease by people who have deep knowledge of how to bridge these conceptual model gaps.
What the tools must not do is increase hurdles for adoption by introducing foreign conceptual models into the understanding process. The Delicious model of multi-term tagging adds a very large conceptual barrier for many & it become problematic for even considering adoption. Optimally, Delicious should not be used alone as a means to introduce social bookmarking or tagging.
We must remove the barriers to entry to these powerful offerings as much as we can as designers and developers. We know the value, we know the future, but we need to extend this. It must be done now, as later is too late and these tools will be written off as just as complex and cumbersome as their predecessors.
If you are a buyer of these tools and services, this is you guideline for the minimum of what you should accept. There is much you should not accept. On this front, you need to push back. It is your money you are spending on the products, implementation, and people helping encourage adoption. Not pushing back on what is not acceptable will greatly hinder adoption and increase the costs for more people to ease the change and adoption processes. Both of these costs should not be acceptable to you.
Multi-term Tag UI Options
Compound Terms
I am starting with what we know to be problematic for broad adoption for input. But, compound terms also create problems for search as well as click retrieval. There are two UI interaction patterns that happen with compound multi-term tags. The first is the terms are mashed together as a compound single word, as shown in this example from Delicious.
The problem here is the mashing the string of terms "architecture is politics" into one compound term "architectureispolitics". Outside of Germanic languages this is problematic and the compound term makes a quick scan of the terms by a person far more difficult. But it also complicates search as the terms need to be broken down to even have LIKE SQL search options work optimally. The biggest problem is for humans, as this is not natural in most language contexts. A look at misunderstood URLs makes the point easier to understand (Top Ten Worst URLs)
The second is an emergent model for compound multi-term tags is using a term delimiter. These delimiters are often underlines ( _ ), dots ( . ), or hyphens ( - ). A multi-term tag such as "enterprise search" becomes "enterprise.search", "enterprise_search" and "enterprise-search".
While these help visually they are less than optimal for reading. But, algorithmically this initially looks to be a simple solution, but it becomes more problematic. Some tools and services try to normalize the terms to identify similar and relevant items, which requires a little bit of work. The terms can be separated at their delimiters and used as properly separated terms, but since the systems are compound term centric more often than not the terms are compressed and have similar problems to the other approach.
Another reason this is problematic is term delimiters can often have semantic relevance for tribal differentiation. This first surface terms when talking to social computing researchers using Delicious a few years ago. They pointed out that social.network, social_network, and social-network had quite different communities using the tags and often did not agree on underlying foundations for what the term meant. The people in the various communities self identified and stuck to their tribes use of the term differentiated by delimiter.
The discovery that these variations were not fungible was an eye opener and quickly had me looking at other similar situations. I found this was not a one-off situation, but one with a fair amount of occurrence. When removing the delimiters between the terms the technologies removed the capability of understanding human variance and tribes. This method also breaks recommendation systems badly as well as hindering the capability of augmenting serendipity.
So how do these tribes identify without these markers? Often they use additional tags to identity. The social computing researchers add "social computing", marketing types add "marketing", etc. The tools then use their filtering by co-occurrence of tags to surface relevant information (yes, the ability to use co-occurrence is another tool essential). This additional tag addition help improve the service on the whole with disambiguation.
Disconnected Multi-term Tags
The use of distinct and disconnected term tags is often the intent for space delimited sites like Delicious, but the emergent approach of mashing terms together out of need surfaced. Delicious did not intend to create mashed terms or delimited terms, Joshua Schachter created a great tool and the community adapted it to their needs. Tagging services are not new, as they have been around for more than two decades already, but how they are built, used, and platforms are quite different now. The common web interface for tagging has been single terms as tags with many tags applied to an object. What made folksonomy different from previous tagging was the inclusion of identity and a collective (not collaborative) voice that intelligent semantics can be applied to.
The downside of disconnected terms in tagging is certainty of relevance between the terms, which leads to ambiguity. This discussion has been going on for more than a decade and builds upon semantic understanding in natural language processing. Did the tagger intend for a relationship between social & network or not. Tags out of the context of natural language constructs provide difficulties without some other construct for sense making around them. Additionally, the computational power needed to parse and pair potential relevant pairings is somethings that becomes prohibitive at scale.
Quoted Multi-term Tags
One of the methods that surfaced early in tagging interfaces was the quoted multi-term tags. This takes becomes #&039;research "social network" blog' so that the terms social network are bound together in the tool as one tag. The biggest problem is still on the human input side of things as this is yet again not a natural language construct. Systematically the downside is these break along single terms with quotes in many of the systems that have employed this method.
What begins with a simple helpful prompt...:
Still often can end up breaking as follows (from SlideShare):
Comma Delimited Tags
Non-space delimiters between tags allows for multi-term tags to exist and with relative ease. Well, that is relative ease for those writing Western European languages that commonly use commas as a string separator. This method allows the system to grasp there are multi-term tags and the humans can input the information in a format that may be natural for them. Using natural language constructs helps provide the ability ease of adoption. It also helps provide a solid base for building a synonym repository in and/or around the tagging tools.
While this is not optimal for all people because of variance in language constructs globally, it is a method that works well for a quasi-homogeneous population of people tagging. This also takes out much of the ambiguity computationally for information retrieval, which lowers computational resources needed for discernment.
Text Box Per Tag
Lastly, the option for input is the text box per tag. This allows for multi-term tags in one text box. Using the tab button on the keyboard after entering a tag the person using this interface will jump down to the next empty text box and have the ability to input a term. I first started seeing this a few years ago in tagging interfaces tools developed in Central Europe and Asia. The Yahoo! Bookmarks 2 UI adopted this in a slightly different implementation than I had seen before, but works much the same (it is shown here).
There are many variations of this type of interface surfacing and are having rather good adoption rates with people unfamiliar to tagging. This approach tied to facets has been deployed in Knowledge Plaza by Whatever s/a and works wonderfully.
All of the benefits of comma delimited multi-term tag interfaces apply, but with the added benefit of having this interface work internationally. International usage not only helps build synonym resources but eases language translation as well, which is particularly helpful for capturing international variance on business or emergent terms.
Summary
This content has come from more than four years of research and discussions with people using tools, both inside enterprise and using consumer web tools. As enterprise moves more quickly toward more cost effective tools for capturing and connecting information, they are aware of not only the value of social tools, but tools that get out the way and allow humans to capture, share, and interact in a manner that is as natural as possible with the tools getting smart, not humans having to adopt technology patterns.
This is a syndicated version of the same post at Optimizing Tagging UI for People & Search :: Personal InfoCloud that has moderated comments available.
Stewart Mader is Now Solo and One to Watch and Hire
There seems to be many people that are joining the ranks of solo service providers around social tools. Fortunately there are some that are insanely great people taking these steps. Stewart Mader is one of these insanely great people now fully out on his own. Stewart Mader's Wiki Adoption Services are the place to start for not only initial stages of thinking through and planning successful wiki projects, but also for working through the different needs and perspectives that come with the 6 month and one year realizations.
Those of you not familiar with Stewart, he wrote the best book on understanding wikis and adoption, Wikipatterns and is my personal favorite speaker on the subject of wikis. Others may have more broadly known names, but can not come close to touching his breadth nor depth of knowledge on the subject. His understandings of wikis and their intersection with other forms and types of social tools is unsurpassed.
I welcome Stewart to the realm of social tool soloists experts. I look forward to one day working on a project with Stewart.
"Building the social web" Full-day Workshop in Copenhagen on June 30th
Through the wonderful cosponsoring of FatDUX I am going to be putting on a full-day workshop Building the Social Web on June 30th in Copenhagen, Denmark (the event is actually in Osterbro). This is the Monday following Reboot, where I will be presenting.
I am excited about the workshop as it will be including much of my work from the past nine months on setting social foundations for successful services, both on the web and inside organizations on the intranet. The workshop will help those who are considering, planning, or already working on social sites to improve the success of the services by providing frameworks that help evaluating and guiding the social interactions on the services.
Space is limited for this workshop to 15 seats and after its announcement yesterday there are only 10 seats left as of this moment.
Lasting Value of Techmeme?
Tristan Louis has a post looking at Is Techmeme Myopic, which is a good look at the lasting value that Techmeme surfaces. This mirrors my use of Techmeme, which is mostly to have a glance at what is being discussed each day. Techmeme has a very temporal value for me as it is a zeitgeist tool that tracks news and memes as they flow and ebb through the technology news realm of the web.
Personally, I like Techmeme as it aggregates the news and conversations, which makes it really easy to skip the bits I do not care about (this is much of what flows through it), but I can focus on the few things that do resonate with me. I can also see a view of who is providing content and I can select sources of information whose viewpoint I value over perspectives I personally place less respect.