Off the Top: Metadata Entries
Showing posts: 16-30 of 60 total posts
Del.icio.us and MyWeb Combo Bookmarklet
I took two of my favorite bookmarklets (for del.icio.us and Yahoo MyWeb 2, put them in my javascript collider to get a Combo Tag Tool (drag this to your browser's bookmark bar.
By clicking on this bookmarklet you get the del.icio.us tag interface populated with the title. You also get a MyWeb entry pop-up window.
I have been seeing the early benefits of Yahoo's MyWeb, but I also want to keep the community I have in del.icio.us. Keeping both up to date and in sync is my goal and hopefully this will help you do the same.
Tagging Article at OK/Cancel
OK/Cancel posted a quick article on tagging I pulled wrote (mostly pulled out of e-mail responses). The article is Tagging for Fun and Finding, which includes mention of folksonomy.
Explaining and Showing Broad and Narrow Folksonomies
I have been explaining the broad and narrow folksonomy in e-mail and in comments on others sites, as well as in the media (Wired News). There has still been some confusion, which is very understandable as it is a different concept that goes beyond a simple understanding of tagging. I have put together a couple graphics that should help provide a means to make this distinction some what clearer. The folksonomy is a means for people to tag objects (web pages, photos, videos, podcasts, etc., essentially anything that is internet addressable) using their own vocabulary so that it is easy for them to refind that information again. The folksonomy is most often also social so that others that use the same vocabulary will be able to find the object as well. It is important to note that folksonomies work best when the tags used to describe objects are in the common vocabulary and not what a person perceives others will call it (the tool works like no other for personal information management of information on the web, but is also shared with the world to help others find the information).
Broad Folksonomy
Let's begin with the broad folksonomy, as a tool like del.icio.us delivers. The broad folksonomy has many people tagging the same object and every person can tag the object with their own tags in their own vocabulary. This lends itself very easy to applying the power law curve (power curve) and/or net effect to the results of many people tagging. The power terms and the long tail both work.
The broad folksonomy is illustrated as follows. 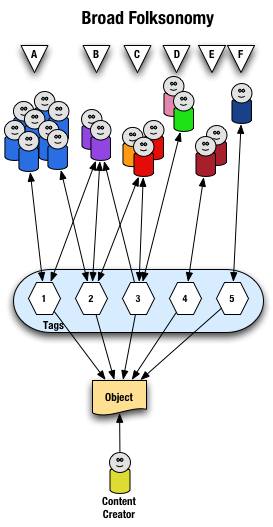
From a high level we see a person creates the object (content) and makes it accessible to others. Other people (groups of people with the same vocabulary represented people blobs and noted with alphabet letters) tag the object (lines with arrows pointing away from the people) with their own terms (represented by numbers). The people also find the information (arrows on lines pointing from the numeric tags back to the people blobs) based on the tags.
Digging a little deeper we see quite a few people (8 people) in group "A" and they have tagged the object with a "1" and a "2" and they use this term to find the object again. Group "B" (2 people) have applied tag "1" and "2" to the object and they use tag terms "1", "2", and "3" to find the information. Group "C" (3 people) have tagged the object with "2" and "3" so that they can find the object. Group "D" has also tagged the object with tag "3" so that they may refind the information this group may have benefitted from the tagging that group "C" provided to help them find the information in the first place. Group "E" (2 people) uses a different term, "4", to tag the object than others before it and uses only this term to find the object. Lastly, group "F" (1 person) uses tag "5" on the object so that they may find it.
Broad Folksonomy and the Power Curve
The broad folksonomy provides a means to see trends in how a broad range are tagging one object. This is an opportunity to see the power law curve at work and show the long-tail.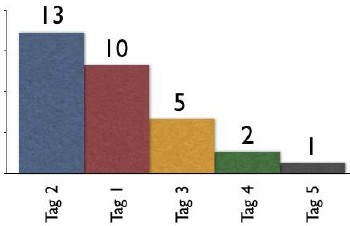
The tags spike with tag "2" getting the largest portion of the tags with 13 entries and tag "1" receiving 10 identical tags. From this point the trends for popular tags are easy to see with the spikes on the left that there are some trends, based on only those that have tagged this object, that could be used extract a controlled vocabulary or at least know what to call the object to have a broad spectrum of people (similar to those that tagged the object, and keep in mind those that tag may not be representative of the whole). We also see those tags out at the right end of the curve, known as the long tail. This is where there is a small minority of people who call the object by a term, but those people tagging this object would allow others with a similar vocabulary mindset to find the object, even if they do not use the terms used by the masses over at the left end of the curve. If we take this example and spread it out over 400 or 1,000 people tagging the same object we will se a similar distribution with even more pronounced spikes and drop-off and a longer tail.
This long tail and power curve are benefits of the broad folksonomy. As we will see the narrow folksonomy does not have the same properties, but it will have benefits. These benefits are non-existent for those just simply tagging items, most often done by the content creator for their own content, as is the means Technorati has done, even with their following tag links to destinations other than Technorati (as they initially had laid out). The benefits of the long tail and power curve come from the richness provided by many people openly tagging the same object.
Narrow Folksonomy
The narrow folksonomy, which a tool like Flickr represents, provides benefit in tagging objects that are not easily searchable or have no other means of using text to describe or find the object. The narrow folksonomy is done by one or a few people providing tags that the person uses to get back to that information. The tags, unlike in the broad folksonomy, are singular in nature (only one tag with the term is used as compared to 13 people in the broad folksonomy using the same tag). Often in the narrow folksonomy the person creating the object is providing one or more of the tags to get things started. The goals and uses of the narrow folksonomy are different than the broad, but still very helpful as more than one person can describe the one object. In the narrow the tags are directly associated with the object. Also with the narrow there is little way of really knowing how the tags are consumed or what portion of the people using the object would call it what, therefore it is not quite as helpful as finding emerging vocabulary or emergent descriptions. We do find that tags used to describe are also used for grouping, which is particularly visible and relevant in Flickr (this is also done in broad folksonomies, but currently not to the degree of visibility that it is done on Flickr, which may be part of the killer interactive environment Ludicorp has created for Flickr).
The narrow folksonomy is illustrated as follows.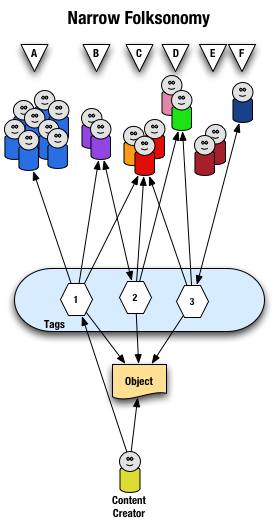
From a high level we see a person creates the object and applies a tag ("1") that represents what they call the object or believe describes the object. There are fewer tags provided than in a broad folksonomy and there is only one of each tag applied to the object. The consumers of the object also can apply tags that help them find the object or describe what they believe are the terms used to describe this object.
A closer look at the interaction between people and the object and tags in a narrow folksonomy shows us that group "A" uses tag "1" to find and come back to the object (did the creator do this on purpose? or did she just tag it with what was helpful to her). We see group "B" also using tag "1" to find the object, but they have tagged the object with tag "2" to also use as a means to find the object. Group "C" uses tag "1","2", and "3" to find the object and we also note this group did not apply any of its own tags to the object as so is only a consumer of the existing folksonomy. We see group "D" uses tags "2" and "3" to find the objects and it too does not add any tags. Group "E" is not able to find the object by using tags as the vocabulary it is using does not match any of the tags currently provided. Lastly, group "F" has their own tag for the object that they alone use to get back to the object. Group "F" did not find the object through existing tags, but may have found the object through other means, like a friend e-mailed them a link or the object was included in a group they subscribe to in their feed aggregator.
We see that the richness of the broad folksonomy is not quite there in a narrow folksonomy, but the folksonomy does add quite a bit of value. The value, as in the case of Flickr, is in text tags being applied to objects that were not findable using search or other text related tools that comprise much of how we find things on the internet today. The narrow folksonomy does provide various audiences the means to add tags in their own vocabulary that will help them and those like them to find the objects at a later time. We are much better off with folksonomies than we were with out them, even if it is a narrow folksonomy being used.
Conclusion
We benefit from folksonomies as the both the personal vocabulary and the social aspects help people to find and retain a tether to objects on the web that are an interest to them. Who is doing the tagging is important to understand and how the tags are consumed is an important factor. This also helps us see that not all tagging is a folksonomy, but is just tagging. Tagging in and of its self is a helpful step up from no tagging, but is no where near as beneficial as opening the tagging to all. Folksonomy tagging can provide connections across cultures and disciplines (an knowledge management consultant can find valuable information from an information architect because one object is tagged by both communities using their own differing terms of practice). Folksonomy tagging also makes up for missing terms in a site's own categorization system/taxonomy. This hopefully has made things a little clearer for all in our understanding the types of folksonomies and tagging and the benefits that can be derived.
This entry first appeared at Personal InfoCloud and comments are open for your use there.
Amazon and A9 Provide Yellow Pages with Photos
Everybody is talking about Amazon's (A9) Yellow Pages today. Amazon has done a decent job bringing photos into their Yellow Pages for city blocks. This is a nice touch, but it is missing some interaction and interconnections between the photos and the addresses, I hope this will come. I really would like to be able to click on a photo and have the Yellow Pages information show up, everything I tried on Clement Street in San Francisco, California did not work that way.
One of the things that really hit me in playing with the tool today at lunch was how the Yellow Pages still suck. I have had problems with the Yellow Pages for..., well ever. I grew up in cross-cultural environments with British and French influences in my day-time care givers growing up. I moved around a fair amount (up and down the West Coast growing up and Europe and the U.S. East Coast). Culture has their own vocabulary (let alone language) for the same items. What I call things, depends on context, but no matter what, the Yellow Pages do not match what I wish to call what I want (or sometimes need).
Today's search I used one of the Amazon search sample, "Optica", which had some nice references. Knowing how I usually approach using the Yellow Pages I search for glasses (as that is what I need to get or need repaired) or contacts. Doing this in a paper Yellow Pages usually returned nothing or pointers to a couple other places. One would thing online Yellow Pages to be different, well they are, they returned nothing related. Glasses returns restaurant supply and automotive window repairs with not one link to eye glasses, nor a reference to "you may be looking for...".
A9 is a great search tool and Amazon.com has great product tools and incredible predictability algorithms, which will be very helpful down the road for the Personal InfoCloud, but the current implementation is still a little rough. I can see where they are heading with this. And I can dream that I would have this available for a mobile device at some point in the next two or three years.
Once very nice piece that was integrated was reviews and ratings of Yellow Pages entries. This is great for the future, once they get filled out. It will also be great once it is available from mobile device (open API so we can start building a useful tool now?). But, it brings my scenario of the future to light rather quickly, where I am standing in front of a restaurant looking at over 100 restaurant reviews on my mobile device. There is no way that I can get through all of these reviews. Our supporting full complement of context tools will be needed to get pulled into play to get me a couple or four good reviews that will mean something to me.
This is but a small slice of the Personal InfoCloud, which is much broader and focusses on enabling the person to leverage the information they have and find. Pairing these two and enabling easy access to that information when it is needed.
Folksonomy Explanations
The past few weeks have seen my inbox flooded with folksonomy questions. I am going to make things easier on my inbox by posting some common discussions here. Many of the items I am posting I have posted else where, but this will also be a great help for me.
There have been many people who have correctly discerned a difference between the two prime folksonomy examples, Flickr and del.icio.us. As I first stated in a comment to Clay Shirky's first article on Folksonomy, there are two derivations of folksonomy. There is a narrow folksonomy and a broad folksonomy. On August 26th I stated...
Clay, you bring in some very good points, particularly with the semantic differences of the terms film, movie, and cinema, which defy normalization. A broad folksonomy, like del.icio.us, allows for many layers of tagging. These many layers develop patterns of consistency (whether they are right or wrong in a professional's view is another matter, but that is what "the people" are calling things). These patterns eventually develop quasi power law for around the folk understanding of the terms as they relate to items.
Combining the power tags of "skateboarding, tricks, movie " (as you point out) will get to the desired information. The hard work of building a hierarchy is not truly essential, but a good tool that provides ease of use to tie the semantic tags is increasingly essential. This is a nascent example of a semantic web. What is really nice is the ability to use not only the power tags, but also the meta-noise (the tags that are not dominant, but add semantic understanding within a community). In the skateboarding example a meta-noise tag could be gnarly that has resonance in the skate community and adds another layer of refinement for them.
The narrow-folksonomy, where one or few users supply the tags for information, such as Flickr, does not supply power tags as easily. One or few people tagging one relatively narrowly distributed item makes normalizing more difficult to employ an tool that aggregates terms. This situation seems to require a tool up front that prompts the individuals creating the tags to add other, possibly, related tags to enhance the findability of the item. This could be a tool that pops up as the user is entering their tags that asks, "I see you entered mac do you want to add fruit, computer, artist, raincoat, macintosh, apple, friend, designer, hamburger, cosmetics, retail, daddy tag(s)?"
This same distinction is brought up on IAWiki' Folksonomy entry.
Since this time Flickr has added the ability for friends and family (and possibly contacts) to add tags, which gives Flickr a broader folksonomy. But, the focus point is still one object that is being tagged, where as del.icio.us has many people tagging one object. The broad-folksonomy is where much of the social benefit can be derived as synonyms and cross-discipline and cross-cultural vocabularies can be discovered. Flickr has an advantage in providing the individual the means to tag objects, which makes it easier for the object to get found.
This brings to the forefront the questions about Google's Gmail, which allows one person the ability to freely tag their e-mail entries. Is Gmail using a folksonomy? Since Gmail was included in the grouping of on-line tools that were in the discussion of what to call these things (along with Flickr and del.icio.us) when folksonomy was coined I say yes. But, my belief that Gmail uses a folksonomy (regular people's categorization through tagging) relates to it using the same means of one person adding tags so that object can be found by them. This is identical to how people tag in Flickr (as proven by the self-referential "me" that is ever prevalent) and del.icio.us. People tag in their own vocabulary for their own retrieval, but they also will tag for social context as well, such as Flickr's "MacWorld" tags. In this case Wikipedia is a little wrong and needs improving.
I suppose Gmail would be a personal folksonomy to the Flickr narrow folksonomy and the del.icio.us broad folksonomy. There are distinct futures for all three folkonomies to grow. Gmail is just the beginning of personal tagging of digital objects (and physical objects tagged with digital information). Lou Rosenfeld hit the nail on the head when he stated, "I'm not certain that the product of folksonomy development will have much long term value on their own, I'll bet dollars to donuts that the process of introducing a broader public to the act of developing and applying metadata will be incredibly invaluable.". These tools, including Gmail, are training for understanding metadata. People will learn new skills if they have a perceived greater value (this is why millions of people learned Palm's Graffiti as they found a benefit in learning the script).
Everybody has immense trouble finding information in their hierarchal folders on their hard drive. Documents and digital objects have more than one meaning than the one folder/directory, in which they reside. Sure there are short cuts, but tracking down and maintaining shortcuts is insanely awkward. Tags will be the step to the next generation of personal information managment.
From Tags to the Future
Merlin hit on something in his I Want a Pony: Snapshots of a Dream Productivity App where he discusses:
Tags - People have strong feelings about metadata and the smart money is usually against letting The User apply his or her own tags and titles for important shared data ("They do it wrong or not at all," the burghers moan). But things are changing for personal users. Two examples? iTunes and del.icio.us. Nobody cares what "metadata" means, but they for damn sure know they want their mp3s tagged correctly. Ditto for del.icio.us, where Master Joshua has shown the world that people will tag stuff that’s important in their world. Don't like someone else's homebrewed taxonomy? Doesn't matter, because you don't need to like it. If I have a repeatable system for tagging the information on just my Mac and it's working for me, that's really all that matters. I would definitley love that tagging ability for the most atomic piece of any work and personal information I touch.
This crossed my radar the same time as I read Jeff Hawkins' discussion about how he came up with Graffiti for Palm devices. He noticed people did not find touch typing intuitive, but they saw the benefit of it and it worked. Conversely in the early 90s people were interacting with handwriting interpreters that often did not understand one's own handwriting. Jeff came up with something that would give good results with a little bit of effort put in. Palm and Graffiti took off. (Personally, I was lucky when I got my first Palm, in that I was on the west coast and waking on east coast time, which gave me two or three hours of time to learn Graffiti before anybody else was awake. It only took two or three days to have it down perfectly).
Merlin's observation fits within these parameters. Where people have not cared at all about metadata they have learned to understand the value of good tags and often do so in a short period of time. iTunes really drives the value of proper tagging home to many (Napster and other shared music environments brought to light tagging to large segments of the population). In a sense folksonomies of del.icio.us and Flickr are decedents of the shared music environments. People could see that tagged objects, whose tags to be edited and leveraged had value in one's ability to find what one is looking for based on those tags.
As the web grew up on deep linking and open environments to find and share information. So to will tagging become that mantra for the masses. All objects, both digital and physical, will be tagged to provide immediacy of information access so to gain knowledge. Learning to search, parse, filter, and leverage predictive tools (ones that understand the person's desires, context, situation, and frame of reference so to quickly (if not instantly) gather, interpret, and make aware the information around the person). Should the person be late for a meeting their predictive filters are going to limit all be the required information, possibly a traffic jam on their normal route as well as their option A route. A person that has some free time may turn up the serendipity impact and get exposed to information they may normally have filtered out of their attention. The key will be understanding tags have value and just as metadata for other objects, like e-mail subject lines, can be erroneous and indicators of spam, our life filters will need the same or similar. We will want to attract information to us that we desire and will need to make smart and informed choices and tags are just one of the means to this end.
Flickr and the Future of the Internet
Peter's post on Flickr Wondering triggers some thoughts that have been gelling for a while, not only about what is good about Flickr, but what is missing on the internet as we try to move forward to mobile use, building for the Personal InfoCloud (allowing the user to better keep information the like attracted to them and find related information), and embracing Ubicomp. What follows is my response to Peter's posting, which I posted here so I could keep better track of it. E-mail feedback is welcome. Enjoy...
You seemed to have hit on the right blend of ideas to bring together. It is Lane's picture component and it is Nadav's integration of play. Flickr is a wonderfully written interactive tool that adds to photo managing and photo sharing in ways that are very easy and seemingly intuitive. The navigations is wonderful (although there are a few tweak that could put it over the top) and the integration of presentational elements (HTML and Flash) is probably the best on the web as they really seem to be the first to understand how to use which tools for what each does best. This leads to an interface that seems quick and responsive and works wonderfully in the hands of many. It does not function perfectly across platforms, yet, but using the open API it is completely possible that it can and will be done in short order. Imagine pulling your favorites or your own gallery onto your mobile device to show to others or just entertain yourself.
Flickr not only has done this phenomenally well, but may have tipped the scales in a couple of areas that are important for the web to move forward. One area is an easy tool to extract a person's vocabulary for what they call things. The other is a social network that makes sense.
First, the easy tool for people to add metadata in their own vocabulary for objects. One of the hinderances of digital environments is the lack of tools to find objects that do not contain words the people seeking them need to make the connection to that object they are desiring. Photos, movies, and audio files have no or limited inherent properties for text searching nor associated metadata. Flickr provides a tool that does this easily, but more importantly shows the importance of the addition of metadata as part of the benefit of the product, which seems to provide incentive to add metadata. Flickr is not the first to go down this path, but it does it in a manner that is light years ahead of nearly all that came before it. The only tools that have come close is HTML and Hyperlinks pointing to these objects, which is not as easy nor intuitive for normal folks as is Flickr. The web moving forward needs to leverage metadata tools that add text addressable means of finding objects.
Second, is the social network. This is a secondary draw to Flickr for many, but it is one that really seems to keep people coming back. It has a high level of attraction for people. Part of this is Flickr actually has a stated reason for being (web-based photo sharing and photo organizing tool), which few of the other social network tools really have (other than Amazon's shared Wish Lists and Linkedin). Flickr has modern life need solved with the ability to store, manage, access, and selectively share ones digital assets (there are many life needs and very few products aim to provide a solution for these life needs or aims to provide such ease of use). The social network component is extremely valuable. I am not sure that Flickr is the best, nor are they the first, but they have made it an easy added value.
Why is social network important? Helping to reduct the coming stench of information that is resultant of the over abundance of information in our digital flow. Sifting through the voluminous seas of bytes needs tools that provide some sorting using predictive methods. Amazon's ratings and that matching to other's similar patterns as well as those we claim as our friends, family, mentors, etc. will be very important in helping tools predict which information gets our initial attention.
As physical space gets annotated with digital layers we will need some means of quickly sorting through the pile of bytes at the location to get a handful that we can skim through. What better tool than one that leverages our social networks. These networks much get much better than they are currently, possibly using broader categories or tags for our personal relationships as well as means of better ranking extended relationships of others as with some people we consider friends we do not have to go far in their group of friends before we run into those who we really do not want to consider relevant in our life structures.
Flickr is showing itself to be a popular tool that has the right elements in place and the right elements done well (or at least well enough) to begin to show the way through the next steps of the web. Flickr is well designed on many levels and hopefully will not only reap the rewards, but also provide inspiration to guide more web-based tools to start getting things right.
Would We Create Hierarchies in a Computing Age?
Lou has posted my question:
Is hierarchy a means to classify and structure based on the tools available at the time (our minds)? Would we have structured things differently if we had computers from the beginning?
Hierarchy is a relatively easy means of classifying information, but only if people are familiar with the culture and topic of the item. We know there are problems with hierarchy and classification across disciplines and cultures and we know that items have many more attributes that which provide a means of classification. Think classification of animals, is it fish, mammal, reptile, etc.? It is a dolphin. Well what type of dolphin, as there are some that are mammal and some that are fish? Knowing that the dolphin swims in water does not help the matter at all in this case. It all depends on the context and the purpose.
Hierarchy and classification work well in limited domains. In the wild things are more difficult. On the web when we are building a site we often try to set hierarchies based on the intended or expected users of the information. But the web is open to anybody and outside the site anybody can link to any thing they wish that is on the web and addressable. The naming for the hyperlink can be whatever helps the person creating the link understand what that link is pointing to. This is the initial folksonomy, hyperlinks. Google was smart in using the link names in their algorithm for helping people find information they are seeking. Yes, people can disrupt the system with Googlebombing, but the it just takes a slightly smarter tool to get around these problems.
You see hierarchies are simple means of structuring information, but the world is not as neat nor simple. Things are far more complex and each person has their own derived means of structuring information in their memory that works for them. Some have been enculturated with scientific naming conventions, while others have not.
I have spent the last few years watching users of a site not understand some of the hierarchies developed as there are more than the one or two user-types that have found use in the information being provided. They can get to the information from search, but are lost in the hierarchies as the structure is foreign to them.
It is from this context that I asked the question. We are seeing new tools that allow for regular people to tag information objects with terms that these people would use to describe the object. We see tools that can help make sense of these tags in a manner that gets other people to information that is helpful to them. These folksonomy tools, like Flickr, del.icio.us, and Google (search and Gmail) provide the means to tame the whole in a manner that is addressable across cultures (including nationalities and language) and disciplines. This breadth is not easily achievable by hierarchies.
So looking back, would we build hierarchies given today's tools? Knowing the world is very complex and diverse do simple hierarchies make sense?
Flexibility in Folksonomies
Nick Mote posts his The New School of Ontologies essay, which is a nice overview of formal classification and folksonomies. The folksonomy is a good approach for bottom-up approach to information finding.
In Nick's paper I get quoted. I have cleaned up the quote that came out of an e-mail conversation. This quote pretty much summaries the many discussions I have had in the past couple months regarding folksonomies. Am I a great fan of the term? Not as much of a fan as what they are doing.
The problem of interest to me that folksonomies are solving is cross-discipline and cross-cultural access to information as well as non-hierarchical information structures. People call items different things depending on culture, discipline, and/or language. The folksonomy seems to be a way to find information based on what a person calls it. The network effect provides for more tagging of the information, which can be leveraged by those who have naming conventions that are divergent from the norm. The power law curve benefits the enculturated, but the tail of the curve also works for those out of the norm.
That Syncing Feeling (text)
My presentation of That Syncing Feeling is available. Currently the text format is available, but a PDF will be available at some point in the future (when more bandwidth is available). This was delivered at Design Engaged in Amsterdam this morning. More to follow...
Personal Information Aggregation Nodes
Agnostic aggregators are the focal point of information aggregation. The tools that are growing increasingly popular for the information aggregation from internet sources are those that permit the incorportation of info from any valid source. The person in control of the aggregator is the one who chooses what she wants to draw in to their aggregator.
People desiring info agregation seemingly want to have control over all sources of info. She wants one place, a central resource node, to follow and to use as a starting point.
The syndication/pull model not only adds value to the central node for the user, but to those points that provide information. This personal node is similar (but conversely) to network nodes in that the node is gaining value as the individual users make use of the node. The central info aggregation node gains value for the individual the more information is centralized there. (The network nodes gain value the more people use them, e.g. the more people that use del.icio.us the more valuable the resource is for finding information.) This personal aggregation become a usable component of the person's Personal InfoCloud.
What drives the usefulness? Portability of information is the driver behind usefulness and value. The originating information source enables value by making the information usable and reusable by syndicating the info. Portabiliry is also important for the aggregators so that information can move easily between devices and formats.
Looking a del.icio.us we see an aggrgator that leverages a social network of people as aggregators and filters. Del.icio.us allows the user to build their own bookmarks that also provides a RSS feed for those bookmarks (actually most everything in del.icio.us provides feeds for most everything) and an API to access the feeds and use then as the user wishes. This even applies to using the feed in another aggregator.
The world of syndication leads to redundant information. This where developments like attention.xml will be extremely important. Attention.xml will parse out redundant info so that you only have one resource. This work could also help provide an Amazon like recommendation system for feeds and information.
The personal aggregation node also provides the user the means to categorize information as they wish and as makes most sense to themselves. Information is often not found and lost because it is not categorized in a way that is meaningful to the person seeking the information (either for the first time or to access the information again). A tool like del.icio.us, as well as Flickr, allows the individual person to add tags (metadata) that allows them to find the information again, hopefully easily. The tool also allows the multiple tagging of information. Information (be it text, photo, audio file, etc.) does not always permit itself easy narrow classification. Pushing a person to use distinct classifications can be problematic. On this site I built my category tool to provide broad structure rather than heirarchial, because it allows for more flexibility and can provide hooks to get back to information that is tangential or a minor topic in a larger piece. For me this works well and it seems the folksonomy systems in del.icio.us and Flickr are finding similar acceptance.
Feed On This
The "My" portal hype died for all but a few central "MyX" portals, like my.yahoo. Two to three years ago "My" was hot and everybody and their brother spent a ton of money building a personal portal to their site. Many newspapers had their own news portals, such as the my.washingtonpost.com and others. Building this personalization was expensive and there were very few takers. Companies fell down this same rabbit hole offering a personalized view to their sites and so some degree this made sense and to a for a few companies this works well for their paying customers. Many large organizations have moved in this direction with their corporate intranets, which does work rather well.
Where Do Personalization Portals Work Well
The places where personalization works points where information aggregation makes sense. The my.yahoo's work because it is the one place for a person to do their one-stop information aggregation. People that use personalized portals often have one for work and one for Personal life. People using personalized portals are used because they provide one place to look for information they need.
The corporate Intranet one place having one centralized portal works well. These interfaces to a centralized resource that has information each of the people wants according to their needs and desires can be found to be very helpful. Having more than one portal often leads to quick failure as their is no centralized point that is easy to work from to get to what is desired. The user uses these tools as part of their Personal InfoCloud, which has information aggregated as they need it and it is categorized and labeled in a manner that is easiest for them to understand (some organizations use portals as a means of enculturation the users to the common vocabulary that is desired for use in the organization - this top-down approach can work over time, but also leads to users not finding what they need). People in organizations often want information about the organization's changes, employee information, calendars, discussion areas, etc. to be easily found.
Think of personalized portals as very large umbrellas. If you can think of logical umbrellas above your organization then you probably are in the wrong place to build a personalized portal and your time and effort will be far better spent providing information in a format that can be easily used in a portal or information aggregator. Sites like the Washington Post's personalized portal did not last because of the cost's to keep the software running and the relatively small group of users that wanted or used that service. Was the Post wrong to move in this direction? No, not at the time, but now that there is an abundance of lesson's learned in this area it would be extremely foolish to move in this direction.
You ask about Amazon? Amazon does an incredible job at providing personalization, but like your local stores that is part of their customer service. In San Francisco I used to frequent a video store near my house on Arguello. I loved that neighborhood video store because the owner knew me and my preferences and off the top of his head he remembered what I had rented and what would be a great suggestion for me. The store was still set up for me to use just like it was for those that were not regulars, but he provided a wonderful service for me, which kept me from going to the large chains that recorded everything about me, but offered no service that helped me enjoy their offerings. Amazon does a similar thing and it does it behind the scenes as part of what it does.
How does Amazon differ from a personalized portal? Aggregation of the information. A personalized portal aggregates what you want and that is its main purpose. Amazon allows its information to be aggregated using its API. Amazon's goal is to help you buy from them. A personalized portal has as its goal to provide one-stop information access. Yes, my.yahoo does have advertising, but its goal is to aggregate information in an interface helps the users find out the information they want easily.
Should government agencies provide personalized portals? It makes the most sense to provide this at the government-wide level. Similar to First.gov a portal that allows tracking of government info would be very helpful. Why not the agency level? Cost and effort! If you believe in government running efficiently it makes sense to centralize a service such as a personalized portal. The U.S. Federal Government has very strong restriction on privacy, which greatly limits the login for a personalized service. The U.S. Government's e-gov initiatives could be other places to provide these services as their is information aggregation at these points also. The downside is having many login names and password to remember to get to the various aggregation points, which is one of the large downfalls of the MyX players of the past few years.
What Should We Provide
The best solution for many is to provide information that can be aggregated. The centralized personalized portals have been moving toward allowing the inclusion of any syndicated information feed. Yahoo has been moving in this direction for some time and in its new beta version of my.yahoo that was released in the past week it allows the users to select the feeds they would like in their portal, even from non-Yahoo resources. In the new my.yahoo any information that has a feed can be pulled into that information aggregator. Many of us have been doing this for some time with RSS Feeds and it has greatly changed the way we consume information, but making information consumption fore efficient.
There are at least three layers in this syndication model. The first is the information syndication layer, where information (or its abstraction and related metadata) are put into a feed. These feeds can then be aggregated with other feeds (similar to what del.icio.us provides (del.icio.us also provides a social software and sharing tool that can be helpful to share out personal tagged information and aggregations based on this bottom-up categorization (folksonomy). The next layer is the information aggregator or personalized portals, which is where people consume the information and choose whether they want to follow the links in the syndication to get more information.
There is little need to provide another personalized portal, but there is great need for information syndication. Just as people have learned with internet search, the information has to be structured properly. The model of information consumption relies on the information being found. Today information is often found through search and information aggregators and these trends seem to be the foundation of information use of tomorrow.
Gordon Rugg and the Verifier Method
In the current Wired Magazine an article on Gordon Rugg - Scientific Method Man (yes, it is the same Gordon Rugg of card sorting notoriety). The article focuses on his solving the Voynich manuscript, actually deciphering it as a hoax. How he goes about solving the manuscript is what really has me intrigued.
Rugg uses a method he has been developing, called the verifier approach, which develops a means critical examination using:
The verifier method boils down to seven steps: 1) amass knowledge of a discipline through interviews and reading; 2) determine whether critical expertise has yet to be applied in the field; 3) look for bias and mistakenly held assumptions in the research; 4) analyze jargon to uncover differing definitions of key terms; 5) check for classic mistakes using human-error tools; 6) follow the errors as they ripple through underlying assumptions; 7) suggest new avenues for research that emerge from steps one through six.
One area that Rugg has used this has been solving cross-discipline terminology problems leading to communication difficulties. He also found that pattern-matching is often used to solve problems or diagnose illness, but a more thorough inquiry may have found a more exact cause, which leads to a better solution and better cure.
Can the verifier method be applied to web development? Information Architecture? Maybe, but the depth of knowledge and experience is still rather shallow, but getting better every day. Much of the confounding issues in getting to optimal solutions is the cross discipline backgrounds as well as the splintered communities that "focus" on claimed distinct areas that have no definite boundaries and even have extensive cross over. Where does HCI end and Usability Engineering begin? Information Architecture, Information Design, Interaction Design, etc. begin and end. There is a lot of "big umbrella" talk from all the groups as well as those that desire smaller distinct roles for their niche. There is a lot of cross-pollination across these roles and fields as they all are needed in part to get to a good solution for the products they work on.
One thing seems sure, I want to know much more about the verifier method. It seems like understanding the criteria better for the verifier method will help frame a language of criticism and cross-boundary peer review for development and design.
Fixing Permalink to Mean Something
This has been a very busy week and this weekend it continues with the same. But, I took two minutes to see if I could solve a tiny problem bugging me. I get links to the main blog, Off the Top, from outside search engines and aggregators (Technorati, etc.) that are referencing content in specific entries, but not all of those entries live on the ever-changing blog home page. All of the entries had the same link to their permanant location. The dumb thing was every link to their permanant home was named the same damn thing, "permalink". Google and other search engines use the information in the link name to give value to the page being linked to. Did I help the cause? No.
So now every permanent link states "permalink for: incert entry title". I am hoping this will help solve the problem. I will modify the other pages most likely next week sometime (it is only a two minute fix) as I am toast.
Now Delicious
Time has been very thin of late. In the past six months or so started noticing an increasing number of links from del.icio.us and started pulling the feeds of some folks I like to follow their reading list into my site feed aggregator. I had about four or five del.icio.us feeds in my aggregator (meta aggregation of other's meta aggregations - MetaAg MetaAg). This past week I was taking medicine that tweaked by sleep patterns so I had some free awake time after midnight and I finally set up my own vanderwal del.icio.us feed.
I like having the ability to pull [meta] tags aggregations that others have used, like security, which is a great help during the day at work. I can also track some topics I keep finding myself at the periphery and ever more interested in as they tie to some personal projects.
I did consider something similar with Feedster, but it was down for updating recently when I had the tiny bit of time to fiddle with setting something up. By the way, Feedster is now Standards-based (not fully valid, but rather close) and it loads very quickly (most of the time).
« Previous | 1 2 3 4 | Next »