Off the Top: Intranet Entries
Showing posts: 16-30 of 43 total posts
Folksonomy Provides 70 Percent More Terms Than Taxonomy
While at the WWW Conference in Banff for the Tagging and Metadata for Social Information Organization Workshop and was chatting with Jennifer Trant about folksonomies validating and identifying gaps in taxonomy. She pointed out that at least 70% of the tags terms people submitted in Steve Museum were not in the taxonomy after cleaning-up the contributions for misspellings and errant terms. The formal paper indicates (linked to in her blog post on the research more steve ... tagger prototype preliminary analysis) the percentage may even be higher, but 70% is a comfortable and conservative number.
Is 70% New Terms from Folksonomy Tagging Normal?
In my discussion with enterprise organizations and other clients that are looking to evaluate their existing tagging services, have been finding 30 percent to nearly 70 percent of the terms used in tagging are not in their taxonomy. One chat with a firm who had just completed updating their taxonomy (second round) for their intranet found the social bookmarking tool on their intranet turned up nearly 45 percent new or unaccounted for terms. This firm knew they were not capturing all possibilities with their taxonomy update, but did not realize their was that large of a gap. In building their taxonomy they had harvested the search terms and had used tools that analyzed all the content on their intranet and offered the terms up. What they found in the folksonomy were common synonyms that were not used in search nor were in their content. They found vernacular, terms that were not official for their organization (sometimes competitors trademarked brand names), emergent terms, and some misunderstandings of what documents were.
In other informal talks these stories are not uncommon. It is not that the taxonomies are poorly done, but vast resources are needed to capture all the variants in traditional ways. A line needs to be drawn somewhere.
Comfort in Not Finding Information
The difference in the taxonomy or other formal categorization structure and what people actually call things (as expressed in bookmarking the item to make it easy to refind the item) is normally above 30 percent. But, what organization is comfortable with that level of inefficiency at the low end? What about 70 percent of an organization s information, documents, and media not being easily found by how people think of it?
I have yet to find any organization, be it enterprise or non-profit that is comfortable with that type of inefficiency on their intranet or internet. The good part is the cost is relatively low for capturing what people actually call things by using a social bookmarking tool or other folksonomy related tool. The analysis and making use of what is found in a folksonomy is the same cost of as building a taxonomy, but a large part of the resource intensive work is done in the folksonomy through data capture. The skills needed to build understanding from a folksonomy will lean a little more on the analytical and quantitative skills side than the traditional taxonomy development. This is due to the volume of information supplied can be orders of magnitude higher than the volume of research using traditional methods.
It is Finally IT and Design in Enterprise (and Small Business)
My recent trip to Northern California to speak at the UIE Web App Summit and meetings in the Bay Area triggered some good ideas. One thread of discovery is Enterprise, as well as small and medium sized business, is looking at not only technology for solutions to their needs, but design.
IT Traditions
Traditionally, the CIO or VP IT (and related upper management roles) have focussed on buying technology "solutions" to their information problems. Rarely have the solutions fixed the problems as there is often a "problem with the users" of the systems. We see the technology get blamed, the implementation team get blamed (many do not grasp the solution but only how to install the tools, as that is the type of service that is purchased), and then the "users need more training".
Breaking the Cycle of Blame and Disappointment
This cycle of blame and disappointment in technology is breaking around a few important realizations in the IT world.
Technology is not a Cure All
First, the technology is always over sold in capability and most often needs extensive modification to get working in any environment (the cost of a well implemented system is usually about the same as a built from scratch solution - but who has the resources to do that). Most CIOs and technology managers are not trusting IT sales people or marketing pitches. The common starting point is from the, "your tool can not do what you state" and then discussions can move from there. Occasionally, the tools actually can do what is promised.Many, decision makers now want to test the product with real people in real situations. Solution providers that are good, understand this and will assist with setting up a demonstration. To help truly assess the product the technical staff in the organization is included in the set-up of the product.
People and Information Needs
Second, the problems are finally being identified in terms of people and information needs. This is a great starting place as it focusses on the problems and the wide variety of personal information workflows that are used efficiently by people. We know that technology solutions that mirror and augment existing workflows are easily adopted and often used successfully. This mirroring workflow also allows for lower training costs (occasionally there is no training needed).
Design with People in Mind
Third, design of the interaction and interface must focus on people and their needs. This is the most promising understanding as it revolves around people and their needs. Design is incredibly important in the success of the tools. Design is not just if it looks pretty (that does help), but how a person is walked through the steps easily and how the tools is easy to interact with for successful outcomes. The lack of good design is largely what has crippled most business tools as most have focussed on appealing to the inner geek of the IT manager. Many IT managers have finally realized that their interface and interaction preferences are not remotely representative of 95 percent of the people who need to or should be using the tools.
It is increasingly understood that designing the interaction and interface is very important. The design task must be done with the focus on the needs of real people who will be using the product. Design is not sprinkling some Web 2.0 magic dust of rounded corners, gradients, and fading yellow highlights, but a much deeper understanding that ease of use and breaking processes into easy steps is essential.
Smile to Many Faces
This understanding that buying a technology solutions is more than buying code to solve a problem, but a step in bringing usable tools in to help people work efficiently with information. This last week I talk to many people in Enterprise and smaller businesses that were the technical managers that were trying to get smarter on design and how they should approach digital information problems. I also heard the decision managers stating they needed better interfaces so the people using the tools could, well use the tools. The technology managers were also coming to grips that their preferences for interfaces did not work with most of the people who need the tools to work.
Technology Companies Go Directly to the Users
I have also been seeing the technology tool makers sitting with their actual people using their tools to drastically improve their tools for ease of use. One President of a technology tool maker explained it as, ":I am tired of getting the blame for making poor tools and losing contracts because the technology decision makers are not connected with the real needs of the people they are buying the tools for." This president was talking to three or four users on problems some of his indirect clients were having with a tool they really needed to work well for them. This guy knows the tech managers traditionally have not bought with the people needing to use the tools in mind and is working to create a great product for those people with wants and needs. He also knows how to sell to the technology managers to get their products in the door, but knows designing for the people using the product is how he stays in the company.
Ghosts of Technology Past, Present, and Future
The past two days have brought back many memories that have reminded me of the advances in technology as well as the reliance on technology.
Ghost of Rich Web Past
I watched a walk through of a dynamic prototype yesterday that echoed this I was doing in 1999 and 2000. Well, not exactly doing as the then heavy JavaScript would blow up browsers. The DHTML and web interfaces that helped the person using the site to have a better experience quite often caused the browser to lock-up, close with no warning, or lock-up the machine. This was less than 100kb of JavaScript, but many machines more than two years old at that time and with browsers older than a year or two old did not have the power. The processing power was not there, the RAM was not there, the graphics cards were not powerful, and the browsers in need of optimizing.
The demonstration yesterday showed concepts that were nearly the exact concept from my past, but with a really nice interface (one that was not even possible in 1999 or 2000). I was ecstatic with the interface and the excellent job done on the prototype. I realized once again of the technical advances that make rich web interfaces of "Web 2.0" (for lack of a better term) possible. I have seen little new in the world of Ajax or rich interfaces that was not attempted in 2000 or 2001, but now they are viable as many people's machines can now drive this beauties.
I am also reminded of the past technologies as that is what I am running today. All I have at my beck and call is two 667MHz machines. One is an Apple TiBook (with 1 GB of RAM) and one is a Windows machine (killer graphics card with 256MB video RAM and 500MB memory). Both have problems with Amazon and Twitter with their rich interfaces. The sites are really slow and eat many of the relatively few resources I have at my disposal. My browsers are not blowing up, but it feels like they could.
Ghost of Technology Present
The past year or two I have been using my laptop as my outboard memory. More and more I am learning to trust my devices to remind me and keep track of complex projects across many contexts. Once things are in a system I trust they are mostly out of my head.
This experience came to a big bump two days ago when my hard drive crashed. The iterative back-ups were corrupted or faulty (mostly due to a permission issue that would alter me in the middle of the night). The full back-up was delayed as I do not travel with an external drive to do my regular back-ups. My regularly scheduled back-ups seem to trigger when I am on travel. I am now about 2.5 months out from my last good full back-up. I found an e-mail back-up that functioned from about 3 weeks after that last full backup. Ironically, I was in the midst of cleaning up my e-mail for back-up, which is the first step to my major back-up, when the failure happened.
I have a lot of business work that is sitting in the middle of that pile. I also have a lot of new contacts and tasks in the middle of that period. I have my client work saved out, but agreements and new pitches are in the mire of limbo.
Many people are trying to sync and back-up their lives on a regular basis, but the technology is still faulty. So many people have faulty syncing, no matter what technologies they are using. Most people have more than two devices in their life (work and home computer, smart phone, PDA, mobile phone with syncable address book and calendar, iPod, and other assorted options) and the syncing still works best (often passably) between two devices. Now when we start including web services things get really messy as people try to work on-line and off-line across their devices. The technology has not caught up as most devices are marketed and built to solve a problem between two devices and area of information need. The solutions are short sighted.
Ghost of the Technosocial Future
Last week I attended the University of North Carolina Social Software Symposium (UNC SSS) and while much of the conversation was around social software (including tagging/folksonomy) the discussion of technology use crept in. The topic of digital identity was around the edges. The topic of trust, both in people and technology was in the air. These are very important concepts (technology use, digital identity, and trusted technology and trusted people). There is an intersection of the technosocial where people communicate with their devices and through their devices. The technology layer must be understood as to the impact is has on communication. Communication mediated by any technology requires an understanding of how much of the pure signal of communication is lost and warped (it can be modified in a positive manner too when there are disabilities involved).
Our digital communications are improving when we understand the limitations and the capabilities of the technologies involved (be it a web browser of many varied options or mobile phone, etc.). Learning the capabilities of these trusted devices and understanding that they know us and they hold our lives together for us and protect our stuff from peering eyes of others. These trusted devices communicate and share with other trusted devices as well as our trusted services and the people in our lives we trust.
Seeing OpenID in action and work well gave me hope we are getting close on some of these fronts (more on this in another post). Seeing some of the great brains thinking and talking about social software was quite refreshing as well. The ability to build solid systems that augment our lives and bring those near in thought just one click away is here. It is even better than before with the potential for easier interaction, collaboration, and honing of ideas at our doorstep. The ability to build an interface across data sets (stuff I was working on in 1999 that shortened the 3 months to get data on your desk to minutes, even after running analytics and working with a GIS interface) can be done in hours where getting access to the wide variety of information took weeks and months in the past. Getting access to data in our devices to provide location information with those we trust (those we did not trust have had this info for some time and now we can take that back) enables many new services to work on our behalf while protecting our wishes for whom we would like the information shared with. Having trusted devices working together helps heal the fractures in our data losses, while keeping it safe from those we do not wish to have access. The secure transmission of our data between our trusted devices and securely shared with those we trust is quickly arriving.
I am hoping the next time I have a fatal hard drive crash it is not noticeable and the data loss is self-healed by pulling things back together from resources I have trust (well placed trust that is verifiable - hopefully). This is the Personal InfoCloud and its dealing with a Local InfoCloud all securely built with trusted components.
System One Takes Information Workflow to a New Level
While at Microlearning Conference 2006 Bruno and Tom demonstrated their System One product. This has to be one of the best knowledge/information tools that I have seen in years. They completely understand simplicity and interaction design and have used it to create an information capture and social software tool for the enterprise. Bruno pointed me to a System One overview screen capture (you do not have to login to get started) that features some of the great elements in System One.
One of the brilliant aspects of System One is their marketing of the product. While it has easily usable wiki elements, heavy AJAX, live search, etc. they do not market these buzzwords, they market the ease of use to capture information (which can become knowledge) and the ease of finding information. The simplicity of the interface and interaction make it one of the best knowledge management tools available. Most knowledge management tools fall down on the information entry perspective. Building tools that are part of your workflow, inclusion of information from those that do not feed the KM tool, is essential and System One is the first tools that I have seen that understands this an delivers a product that proves they get it.
The enterprise social software market is one that is waiting to take off, as there is a very large latent need (that has been repressed by poor tools in the past). System One tool is quite smart as they have built e-mail search, file access, Google live file search (you type in the wiki (you do not need to know it is a wiki) and the terms used are searched in Google to deliver a rather nice contextual search. This built in search solves the Google complexity of building solid narrow search queries, but the person using the system just needs to have the capability to enter information into the screen.
Those of us that are geeks find Google queries a breeze, but regular people do not find it easy to tease out the deeply buried gems of information hidden in Google. Surfacing people who are considered experts, or atleast connectors to experts on subjects is part of the System One tool as well and this is an insanely difficult task in an enterprise.
My only wish was that I worked in an organization that would be large enough to use this tool, or there was a personal version I could use to capture and surface my own information when I am working.
You may recognize System One as the developer of retreivr, the Flickr interactive tool that allows you to draw a simple picture and their tool will find related photos in Flickr based on the drawing's pattern and colors. It is a brilliant tool, but not as smart as their main product.
To the Skies Again
I am off again, but this time I have clothes out of the cleaners and laundry done. The turn around from last trip to this trip was only a couple days. I am looking forward to being home for a bit, after this trip. I have about 18 hours of travel before I get where I am going.
I am quite looking forward to being with many people that are passionate about microcontent and microlearning. A conversation in early 2001 got me completely hooked on microcontent and its possibilities. We are finally beginning to see tangents of the microcontent world slip into use in the world of the general public. APIs, aggregation, tracking, metadata access, pushing to mobile, etc. are all components, when they work right. We are only a slice of the way there, but each little step gets better and better.
Developing the Web for Whom?
Google Web Developer Toolkit for the Closed Web
Andrew in his post "Reading user interface libraries" brings in elements of yesterday's discussion on The Battle to Build the Personal InfoCloud. Andrew brings up something in his post regarding Google and their Google Web Developer Toolkit (GWT. He points out it is in Java and most of the personal web (or new web) is built in PHP, Ruby [(including Ruby on Rails), Python, and even Perl].
When GWT was launched I was at XTech in Amsterdam and much of the response was confusion as to why it was in Java and not something more widely used. It seems that by choosing Java for developing GWT it is aiming at those behind the firewall. There is still much development on the Intranet done in Java (as well as .Net). This environment needs help integrating rich interaction into their applications. The odd part is many Intranets are also user-experience challenged as well, which is not one of Google's public fortés.
Two Tribes: Inter and Intra
This whole process made me come back to the two differing worlds of Internet and Intranet. On the Internet the web is built largely with Open Source tools for many of the big services (Yahoo, Google, EBay, etc.) and nearly all of the smaller services are Open Source (the cost for hosting is much much lower). The Open Source community is also iterating their solutions insanely fast to build frameworks (Ruby on Rails, etc.) to meet ease of development needs. These sites also build for all operating systems and aim to work in all modern browsers.
On the Intranet the solutions are many times more likely to be Java or .Net as their is "corporate" support for these tools and training is easy to find and there is a phone number to get help from. The development is often for a narrower set of operating systems and browsers, which can be relatively easy to define in a closed environment. The Google solution seems to work well for this environment, but it seems that early reaction to its release in the personal web it fell very flat.
13 Reasons
A posting about Top 13 reasons to CONSIDER the Microsoft platform for Web 2.0 development and its response, "Top 13 reasons NOT to consider the Microsoft platform for Web 2.0 development" [which is on a .Net created site] had me thinking about these institutional solutions (Java and .Net) in an openly developed personal web. The institutional solutions seem like they MUST embrace the open solutions or work seamlessly with them. Take any one of the technical solutions brought up in the Microsoft list (not including Ray Ozzie or Robert Scoble as technical solutions) and think about how it would fit into personal site development or a Web 2.0 developed site. I am not so sure that in the current state of the MS tools they could easily drop in with out converting to the whole suite. Would the Visual .Net include a Python, PHP, Ruby, Ruby On Rails, or Perl plug-in?The Atlas solution is one option in now hundreds of Ajax frameworks. To get use the tools must had more value (not more cost or effort) and embrace what is known (frogs are happy in warm water, but will not enter hot water). Does Atlas work on all browsers? Do I or any Internet facing website developer want to fail for some part of their audience that are using modern browsers?
The Web is Open
The web is about being browser agnostic and OS agnostic. The web makes the OS on the machine irrelevant. The web is about information, media, data, content, and digital objects. The tools that allow us to do things with these elements are increasingly open and web-based and/or personal machine-based.
Build Upon Open Data and Open Access
The web is moving to making the content elements (including the microconent elements) open for use beyond the site. Look at the Amazon Web Services (AWS) and the open APIs in the Yahoo Developer Network. Both of these companies openly ease community access and use of their content and services. This draws people into Amazon and Yahoo media and properties. What programming and scripting languages are required to use these services? Any that the developer wants.. That is right, unlike Google pushing Java to use their solution, Amazon and Yahoo get it, it is up to the developer to use what is best for them. What browsers do the Amazon and Yahoo solutions work in? All browsers.
I have been watching Microsoft Live since I went to Search Champs as they were making sounds that they got it too. The Live Clipboard [TechCrunch review] that Ray Ozzie gave at O'Reilly ETech is being developed in an open community (including Microsoft) for the whole of the web to use. This is being done for use in all browsers, on all operating systems, for all applications, etc. It is open. This seems to show some understanding of the web that Microsoft has not exhibited before. For Microsoft to become relevant, get in the open web game, and stay in the game they must embrace this approach. I am never sure that Google gets this and there are times where I am not sure Yahoo fully gets it either (a "media company" that does not support Mac, which the Mac is comprised of a heavily media-centric community and use and consume media at a much higher rate than the supported community and the Mac community is where many of the trend setters are in the blogging community - just take a look around at SXSW Interactive or most any other web conference these days (even XTech had one third of the users on Mac).
Still an Open Playing Field
There is an open playing field for the company that truly gets it and focusses on the person and their needs. This playing field is behind firewalls on Intranet and out in the open Internet. It is increasingly all one space and it continues to be increasingly open.
Upcoming Conferences I am Presenting at and Attending
Okay, things have been quite busy here. But, here will be changing as I am hitting the skies a bit in the short term. This means I may be near you so reach out and we can hang out and chat. I am completely looking forward to all the places on my schedule and seeing all of the people.
XTech
I am off to Amsterdam, Netherlands (no not that other one) this week to speak at XTech. I will be presenting Developing for the Personal InfoCloud on Thursday at 11:45 in the morning.
BarCamp Amsterdam
On Saturday I will be attending BarCamp Amsterdam for part of the time.
Seattle Area
Following the Amsterdam trip I should be in the Seattle area for work. I don't have dates as of yet, but if you shoot an e-mail I will be sure and connect.
Microlearning 2006 Conference
I will be heading to Innsbruck, Austria for the Microlearning Conference and preconference (June 7). I will be talking about microcontent in the Personal InfoCloud and our ability and desire to manage it (one means of doing this is folksonomy, but will be discussing much more).
Following Innsbruck I may be in Europe a bit longer and a little farther north. I will be in Amsterdam just following the conference, but beyond that my schedule has not yet fully jelled.
WebVisions 2006
I will be heading to WebVisions 2006 in Portland, Oregon July 20th and 21st. I will be speaking on Friday the 21st about Tagging in the Real World. This will look at how people are making use of tagging (particularly tagging services) and looking at the best practices.
The Fall
In September it looks like I will be in Brighton, UK for a wonderful event. I should also be in Australia later in September for another conference.
As these events get closer, I will be letting you know.
Yes, I know I need to be publishing this information in hCal, but I have been quite busy of late. But, I am moving in that direction very soon. You can also follow what I am watching and attending in Upcoming for vanderwal.
Web 2.0 Dead?
It was bound to happen sooner or later, but it was a little sooner than expected. Richard McMannus explains why Web 2.0 jumped the shark as an follow-up to his Web 2.0 is dead. R.I.P. post. This pronouncement has an impact as he is co-writing a book on Web 2.0 for O'Reilly Books (with Joshua Porter) and writes Web 2.0 Explorer on ZD Net. In Richard's explanation he gives the prime reason is to get away from the hype and cynicism.
Tim O'Reilly describes Web 2.0 in rather long detail. But in the more than a year that the term has been around it has not been used in any specific specific sense and it quickly turned into a buzzword with little meaning. There are some profoundly different things taking place on the web, when we compare it to the web five years ago. These things seem to be best described by their terms and pointing to what has changed and where we are going now. Richard writes that he will still largely be writing about the same things, but will not be using the Web 2.0 moniker.
The Rich Interface
During the past six to nine months one could easily see that the term Web 2.0 getting flattened into hype and mis-understanding. Many articles were written about new technologies that were changing the landscape, but neither were the technologies new, nor were they doing much of anything different than sites were doing or trying to do in the previous three to five years. AJAX was not new, it was a new name for xmlhttprequest (which most web developer worth much of anything knew about, but knew there was little browser adoption outside of Microsoft IE). Jesse James Garrett provided a much easier means of calling the long term, mostly to talk more easily about what Flickr and Google (in Gmail and Google maps) had been doing in the past year using it as part of their rich interfaces. The rich interfaces were absolutely nothing new as Flash had been providing the exact rich interface capability for years. The problem was much of the design world had not worked through its documentation and design specifications for a rich interface using Flash, but they jumped all over AJAX with out ever working through solutions to the problems of state, (re)addressing information, breaking the back button, addressable steps in a process, etc. Web browsers growing up and becoming consistent and more processing power and memory on the machines under the browsers have enabled the rich interface more than anything that gets credit for being new.
Web as Platform
The web as a platform is a great step forward, but it is anything but new, just ask the folks at Salesforce. But it has been embraced as a replacement for the desktop . The downside is most people do not have continuous access (or anything near it) and many do not want it. People have set workflows that cross many devices, contexts, and information uses. Thinking the web is the only way is just as short-sited as closed desktop applications. The web as a platform is insanely helpful, but it should not be the only platform. We have to work towards cross-platfoms and cross-device use development as an end not just the web.
Forbidden Term
Very quickly this year the Web 2.0 term was forbidden from usage from many conferences and large meetings I went to. It was forbidden as by that point it had lost its meaning and using the more direct terms, like social networking, social bookmarks, rich interface for mail, web as an application platform, etc. It was also noted that people should not say the new web, with out explaining why they thought it was new. There needs to be clarity in understanding so we can communicate, and Web 2.0 did not provide that as it was an umbrella term that was used as a buzz word to replace specific changes people did not understand.
Without a Term How to We Understand
There have been a handful of people who have been writing on the Web 2.0 changes and landscape and using the term well and describing the components that are being used in new ways. Richard was one and his writing partner Joshua is another. The group that is aggregated at Web 2.0 Workgroup are most of the rest.
With out the term Web 2.0 it will be tough, but it was more a marker of a confluence of many different things that shifted than a bright line in one or two areas. Understanding what has changed will make sense, which is a large part or what Joshua has been doing and a small handful of others. When the confluence is the streams and rivers of technology, social interaction (as Bruce Sterling calls it "technosocial"), interface, web services, application that provide uses that are needed, cultural and social changes along the lines of privacy (this could swing back massively), cultural changes with more people having comfort with social interactions using technology, trust, etc. take place there will be problems describing it. There will also be only a rare few that can cross the chasms and grasp, make sense of the subtle as well as vast changes, and explain them intelligently and simply to others. As the majority of writing has proven it is a very rare few indeed that have the background and wit to handle this challenge.
Now that I am at the end of the brain dump (some of it long festering), I think I am a wee bit sad to see the term losing traction. But, I don't have to think had to remember one of the vast many of poor articles that every journal has had somebody write.
In full disclosure I spoke on the BayCHI Web 2.0 Panel held at Parc in August. Been writing and speaking on digital information use across devices and platforms for three or four years and the underlying information architecture that is needed to support it. In this past year I frame the need for it as a change from the "I go get web" to the "Come to me web" (not quite equivalent to the push/pull analogy, but I will explain this later for those that have not heard the presentations or me just ramble about it). I felt it important to frame what I change I was talking about rather than rely on the Web 2.0 moniker.
Letting People Express What They Know
At the Euro IA Summit Euan Semple of BBC made a response to how you give people time to blog on their internal sites, "How you run an organization with out letting people express what they know, that I do not know.". This I think is an incredible frame for any organization to capture information to better its self.
No More Waiting...
I suppose I should note here that the last day at my current job will be October 6, 2005. I am not sure what the next full step will be, but I will be focussing my full attention what I have been passionate about for the past few years. Rather than spending a few hours every evening and weekends on my passions, it will become my full-time job. The details will show themself in the next few weeks and months. I need the time to persue some options and have time to think about and consider others.
For the last couple years I have joked I commute to my day job, but telecommute to my private life. Well, my private life is where most of the Model of Attraction, Personal InfoCloud, Local InfoCloud, and folksonomy work takes place. Pieces of this work make it into the day job, but not enough to keep me excited or engaged. I am really wanting to see more great work and products that easily functions for people across devices, across platforms, and is easy for real people to use and reuse.
The world has been shifting to a "come to me web". We are seeing the easiest way to make this easier for people attract what they want this is to learn what each person has an interest in, as well as what their friends and peers have interests in. This will help the findability of information and media for people, but the real problem is in the re-findability of that same information and media for people so they can have what the want and desire at their finger tips when they want it and need it. We have all of the technology needed to make this happen, but it needs research, quick iterative development, and removing the walls around the resources (information/media, unwarranted device restrictions (American cell companies have created the failure of the missing robust mobile market), and unwarranted software restrictions). Paying attention to people and people's interactions is the real key to getting things right, not trying to beat your competitor (focussing on the wrong goal gets the poor results). Make the products people need that solve problems people have (with out introducing problems) and you will have a winner. People have so many needs and desires and every person is different so one solution will not fit all and we should never make things just one way.
These will be a long few weeks with more small steps for me. There is a lot to get done and to consider in the next few weeks. In this is preparing for speaking and traveling on top of the other needed work to be done to prep for this next step. I will pop back up and fill you in when I know more. but, the count down has begun.
Designing for the Personal InfoCloud presentation at WebVisions 2005 Wrap-up
I have posted my presentation from yesterday's session at WebVisions, in Portland, Oregon. The files, Designing for the Personal InfoCloud are in PDF format and weigh in at 1.3MB.
I really had a blast at the conference and wish I could have been there the whole day. I will have to say from the perspective of a speaker it is a fantastically run conference. Brad Smith of Hot Pepper Studios did a knock out job pulling this conference together. It should be on the must attend list for web developers. I was impressed with the speakers, the turn out, and how well everything was run. Bravo!
WebVisions is held in one of my favorite cities, Portland, Oregon, which has some of the best architecture and public planning of any North American city. I have more than 300 photos I have taken in 48 hours and will be posting many at Flickr in the next couple of days.
Social Machines in MIT Technology Review
In the August issue of MIT Technology Review in Wade Roush's cover story on Social Machines (posted on Wade's site) I get a nice quote. The article is well worth the read, even worth picking up the issue when it hits the stands. The article covers the social, mobile, and continuous computing world that some of us live in and many more will be doing soon. Those of us working at the front of the curve are working on ways to make it smoother for those who will follow along soon.
Convergence and the seamless transfer from stationary computing to continuous computing leads to drastically different interactions with information and media. We are already seeing the shift of people using mobile phones as just a voice communication medium to one that includes text and media interactions, or the from people listening to their mobile phones to looking at their mobile phones. Three years ago I made this shift and I was extremely frustrated as I had many more desires than my mobile phones could assuage. But, it is getting better today even if it takes more human interaction than is really needed to sync information, let alone have moved close to me (or whomever is the wanting to have the information or media stay attracted to themselves or have attracted in certain situations). It is this that is my focus of the Model of Attraction and the focus of the Personal InfoCloud.
State is the Web
The use and apparent mis-use of state on the web has bugged me for some time, but now that AJAX, or whatever one wants to call "XMLHttpRequests", is opening the door to non-Flash developers to ignore state. The latest Adaptive Path essay, It's A Whole New Internet, quotes Michael Buffington, "The idea of the webpage itself is nearing its useful end. With the way Ajax allows you to build nearly stateless applications that happen to be web accessible, everything changes." And states, "Where will our bookmarks go when the idea of the 'webpage' becomes obsolete?"
I agree with much of the article, but these statements are wholly naive in my perspective. Not are they naive, but they hold up examples of the web going in the wrong direction. Yes, the web has the ability to build application that are more seemless thanks to the that vast majority of people using web browsers that can support these dynamic HTML techniques (the techniques are nothing new, in fact on intranets many of us were employing them four or five years ago in single browser environments).
That is not the web for many, as the web has been moving toward adding more granular information chunks that can be served up and are addressible. RESTful interfaces and "share this page" links are solutions. The better developers in the Flash community has been working to build state into their Flash presentations to people can link to information that is important, rather than instructing others to click through a series of buttons or wait through a few movies to get to desired/needed information. The day of one stateless interface for all information was behind us, I hope to hell it is not enticing a whole new generation of web developers to lack understanding of state.
Who are providing best examples? Flickr and Google Maps are two that jump to mind. Flickr does one of the best jobs with fluid interfaces, while keeping links to state that is important (the object that the information surrounds, in this case a photograph). Google Maps are stunning in their fluidity, but during the whole of one's zooming and scrolling to new locations the URL remains the same. Google Map's solution is to provide a "Link to this page" hyperlink (in my opinion needs to be brought to the visual forefront a little better as I have problems getting people to recognize the link when they have sent me a link to maps.google.com rather than their intended page).
Current examples of a poor grasp of state is found on the DUX 2005 conference site. Every page has the same URL, from the home page, to submission page, to about page. You can not bookmark the information that is important to yourself, nor can you send a link to the page your friend is having problems locating. The site is stateless in all of its failing glory. The designer is most likely not clueless, just thoughtless. They have left out the person using the site (not users, as I am sure their friends whom looked at the design thought it was cool and brilliant). We have to design with people using and resusing our site's information in mind. This requires state.
When is State Helpful?
If you have important information that the people using your site may want to directly link to, state is important as these people will need a URL. If you have large datasets that change over time and you have people using the data for research and reports, the data must have state (in this case it is the state of the data at some point in time). Data that change that does not have state will only be use for people that enjoy being selected as a fool. Results over time will change and all good academic research or professional researchers note the state of the data with time and date. All recommendations made on the data are only wholly relevant to that state of the data.
Nearly all blogging tools have "permalinks", or links that link directly to an unchanging URL for distinct articles or postings, built into the default settings. These permalinks are the state function, as the main page of a blog is fluid and ever changing. The individual posts are the usual granular elements that have value to those linking to them (some sites provide links down to the paragraph level, which is even more helpful for holding a conversation with one's readers).
State is important for distinct chunks of information found on a site. Actions do not seem state-worthy for things like uploading files, "loading screens", select your location screens (the pages prior and following should have state relative to the locations being shown on those pages), etc.
The back button should be a guide to state. If the back button takes the user to the same page they left, that page should be addressable. If the back button does not provide the same information, it most likely should present the same information if the person using the site is clicking on "next" or "previous". When filling out an application one should be able to save the state of the application progress and get a means to come back to that state of progress, as people are often extremely aggravated when filling out longs forms and have to get information that is not in reach, only to find the application times out while they are gone and they have to start at step one after being many steps into the process.
State requires a lot of thought and consideration. If we are going to build the web for amateurization or personal information architectures that ease how people build and structure their use of the web, we must provide state.
Explaining and Showing Broad and Narrow Folksonomies
I have been explaining the broad and narrow folksonomy in e-mail and in comments on others sites, as well as in the media (Wired News). There has still been some confusion, which is very understandable as it is a different concept that goes beyond a simple understanding of tagging. I have put together a couple graphics that should help provide a means to make this distinction some what clearer. The folksonomy is a means for people to tag objects (web pages, photos, videos, podcasts, etc., essentially anything that is internet addressable) using their own vocabulary so that it is easy for them to refind that information again. The folksonomy is most often also social so that others that use the same vocabulary will be able to find the object as well. It is important to note that folksonomies work best when the tags used to describe objects are in the common vocabulary and not what a person perceives others will call it (the tool works like no other for personal information management of information on the web, but is also shared with the world to help others find the information).
Broad Folksonomy
Let's begin with the broad folksonomy, as a tool like del.icio.us delivers. The broad folksonomy has many people tagging the same object and every person can tag the object with their own tags in their own vocabulary. This lends itself very easy to applying the power law curve (power curve) and/or net effect to the results of many people tagging. The power terms and the long tail both work.
The broad folksonomy is illustrated as follows. 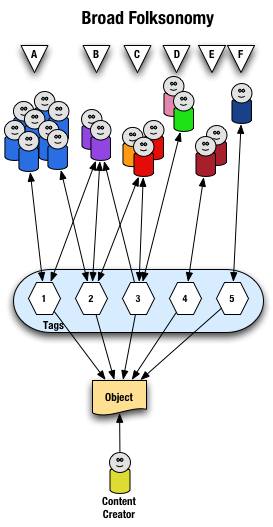
From a high level we see a person creates the object (content) and makes it accessible to others. Other people (groups of people with the same vocabulary represented people blobs and noted with alphabet letters) tag the object (lines with arrows pointing away from the people) with their own terms (represented by numbers). The people also find the information (arrows on lines pointing from the numeric tags back to the people blobs) based on the tags.
Digging a little deeper we see quite a few people (8 people) in group "A" and they have tagged the object with a "1" and a "2" and they use this term to find the object again. Group "B" (2 people) have applied tag "1" and "2" to the object and they use tag terms "1", "2", and "3" to find the information. Group "C" (3 people) have tagged the object with "2" and "3" so that they can find the object. Group "D" has also tagged the object with tag "3" so that they may refind the information this group may have benefitted from the tagging that group "C" provided to help them find the information in the first place. Group "E" (2 people) uses a different term, "4", to tag the object than others before it and uses only this term to find the object. Lastly, group "F" (1 person) uses tag "5" on the object so that they may find it.
Broad Folksonomy and the Power Curve
The broad folksonomy provides a means to see trends in how a broad range are tagging one object. This is an opportunity to see the power law curve at work and show the long-tail.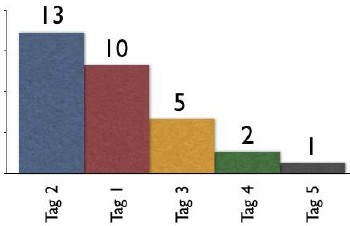
The tags spike with tag "2" getting the largest portion of the tags with 13 entries and tag "1" receiving 10 identical tags. From this point the trends for popular tags are easy to see with the spikes on the left that there are some trends, based on only those that have tagged this object, that could be used extract a controlled vocabulary or at least know what to call the object to have a broad spectrum of people (similar to those that tagged the object, and keep in mind those that tag may not be representative of the whole). We also see those tags out at the right end of the curve, known as the long tail. This is where there is a small minority of people who call the object by a term, but those people tagging this object would allow others with a similar vocabulary mindset to find the object, even if they do not use the terms used by the masses over at the left end of the curve. If we take this example and spread it out over 400 or 1,000 people tagging the same object we will se a similar distribution with even more pronounced spikes and drop-off and a longer tail.
This long tail and power curve are benefits of the broad folksonomy. As we will see the narrow folksonomy does not have the same properties, but it will have benefits. These benefits are non-existent for those just simply tagging items, most often done by the content creator for their own content, as is the means Technorati has done, even with their following tag links to destinations other than Technorati (as they initially had laid out). The benefits of the long tail and power curve come from the richness provided by many people openly tagging the same object.
Narrow Folksonomy
The narrow folksonomy, which a tool like Flickr represents, provides benefit in tagging objects that are not easily searchable or have no other means of using text to describe or find the object. The narrow folksonomy is done by one or a few people providing tags that the person uses to get back to that information. The tags, unlike in the broad folksonomy, are singular in nature (only one tag with the term is used as compared to 13 people in the broad folksonomy using the same tag). Often in the narrow folksonomy the person creating the object is providing one or more of the tags to get things started. The goals and uses of the narrow folksonomy are different than the broad, but still very helpful as more than one person can describe the one object. In the narrow the tags are directly associated with the object. Also with the narrow there is little way of really knowing how the tags are consumed or what portion of the people using the object would call it what, therefore it is not quite as helpful as finding emerging vocabulary or emergent descriptions. We do find that tags used to describe are also used for grouping, which is particularly visible and relevant in Flickr (this is also done in broad folksonomies, but currently not to the degree of visibility that it is done on Flickr, which may be part of the killer interactive environment Ludicorp has created for Flickr).
The narrow folksonomy is illustrated as follows.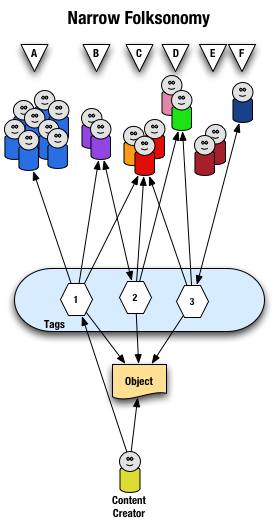
From a high level we see a person creates the object and applies a tag ("1") that represents what they call the object or believe describes the object. There are fewer tags provided than in a broad folksonomy and there is only one of each tag applied to the object. The consumers of the object also can apply tags that help them find the object or describe what they believe are the terms used to describe this object.
A closer look at the interaction between people and the object and tags in a narrow folksonomy shows us that group "A" uses tag "1" to find and come back to the object (did the creator do this on purpose? or did she just tag it with what was helpful to her). We see group "B" also using tag "1" to find the object, but they have tagged the object with tag "2" to also use as a means to find the object. Group "C" uses tag "1","2", and "3" to find the object and we also note this group did not apply any of its own tags to the object as so is only a consumer of the existing folksonomy. We see group "D" uses tags "2" and "3" to find the objects and it too does not add any tags. Group "E" is not able to find the object by using tags as the vocabulary it is using does not match any of the tags currently provided. Lastly, group "F" has their own tag for the object that they alone use to get back to the object. Group "F" did not find the object through existing tags, but may have found the object through other means, like a friend e-mailed them a link or the object was included in a group they subscribe to in their feed aggregator.
We see that the richness of the broad folksonomy is not quite there in a narrow folksonomy, but the folksonomy does add quite a bit of value. The value, as in the case of Flickr, is in text tags being applied to objects that were not findable using search or other text related tools that comprise much of how we find things on the internet today. The narrow folksonomy does provide various audiences the means to add tags in their own vocabulary that will help them and those like them to find the objects at a later time. We are much better off with folksonomies than we were with out them, even if it is a narrow folksonomy being used.
Conclusion
We benefit from folksonomies as the both the personal vocabulary and the social aspects help people to find and retain a tether to objects on the web that are an interest to them. Who is doing the tagging is important to understand and how the tags are consumed is an important factor. This also helps us see that not all tagging is a folksonomy, but is just tagging. Tagging in and of its self is a helpful step up from no tagging, but is no where near as beneficial as opening the tagging to all. Folksonomy tagging can provide connections across cultures and disciplines (an knowledge management consultant can find valuable information from an information architect because one object is tagged by both communities using their own differing terms of practice). Folksonomy tagging also makes up for missing terms in a site's own categorization system/taxonomy. This hopefully has made things a little clearer for all in our understanding the types of folksonomies and tagging and the benefits that can be derived.
This entry first appeared at Personal InfoCloud and comments are open for your use there.
Books Read in 2004
I bought and read one standout book this year, Malcolm McCullough's Digital Ground mixed in with many more that I enjoyed. Digital Ground stood out as it combined a lot of things I had been thinking about, but had not quite pulled together. It brought interaction design front and center in the ubiquitous computing and mobile computing spectrum. I have been working on the Personal InfoCloud for a few years now and this really moved my thinking forward in a great leap. I considering better questions and realizing there are many next step, but few of these next steps the design community (in the broad user experience design sense) seems ready for at this time. One of the key components that is not was thought through is interaction design and the difference place makes in interaction design. It was one book that got my highlighter out and marking up, which few books have done in the past couple years.
I greatly enjoyed the troika of books on the mind that came out in 2004. The first was Mind Wide Open by Stephen Berlin Johnson, which was a relatively easy read and brought to mind much of how we use are minds in our daily lives, but also how we must think of the coginitive processes in our design work. Mind Wide Open focussed on improving one's attention, which is helpful in many situations, but I have had a running question ever since reading the book regarding focus of attention and creative problem resolution (I do not see focus of attention good for creative problem resolution).
The second book was On Intelligence by Jeff Hawkins. On Intelligence is similar to Mind Wide Open, but with a different frame of reference. Hawkins tries to understand intelligence through refocussing on predictive qualities and not so much on results based evaluation (Turing Test). I really like the Hawkins book, which throws in some guesses in with scientifically proven (unfortunately these guesses are not easily flagged), but the predictive qualities and the need for computing to handle some of the predictive qualities to improve people's ability to handle the flood of information.
Lastly, for in the mind book troika I picked up and have been reading Mind Hacks by Tom Stafford and Matt Webb. This is one of the O'Reilly Hack series of books, but rather than focussing on software, programming, or hardware solutions these to gents focus on the mind. Mind tricks, games, and wonderful explainations really bring to life the perceptions and capabilites of the grey lump in our head. I have been really enjoying this as bedtime reading.
Others in related genres that I have read this year, Me++: The Cyborg Self in the Networked City by William Mitchell, which was not a soaring book for me, mostly because Ihad just read Digital Ground and it should have been read in the opposite order, if I had cared to. Linked: How Everything is Connected to Everything Else and What it Meands by Albert-Laszlo Barabasi was a wonderful read, once I got through the first 20 pages or so. I had purched the book in hardback when it first came out and I was not taken by the book in the first 20 pages. This time I got past those pages and loved every page that followed. Barabasi does a wonderful job explaining and illustrating the network effect and the power curve. This has been incorporated into my regular understanding of how things work on the internet. I have learned not to see the power curve as a bad thing, but as something that has opportunities all through out the curve, even in the long tail. On the way back from Amsterdam I finally read Invisible Cities by Italo Calvino, which was quite a wonderful end to that trip.
I picked up a few reference books that I enjoyed this year and have bought this year and have proven to be quite helpful. 250 HTML and Web Design Secrets by Molly Holzschlag. CSS Cookbook by Chris Schmitt. More Eric Meyer on CSS by Eric Meyer.
On the Apple/Mac front the following reference books have been good finds this year. Mac OS X Unwired by Tom Negrino and Dori Smith. Mac OS X Power Hound by Rob Griffths.
Two very god books for those just starting out with web design (Molly's book above would be a good choice also). Web Design on a Shoestring by Carrie Bickner. Creating a Web Page with HTML : Visual QuickProject Guide by Elizabeth Castro.
The year started and ended with two wonderful Science Fiction romps. Eastern Standard Tribe by Cory Doctorow. Jennifer Government by Max Barry.
Update: I knew I would miss one or more books. I am very happy that 37signals published their Defensive Design for the Web: How To Improve Error Messages, Help, Forms, and Other Crisis Points, as it is one of the best books for applications and web development on how to get the little things right. The tips in the book are essential for getting things right for the people using the site, if these essentials are missed the site or application is bordering on poor. Professionally built sites and applications should work toward meeting everything in this book, as it is not rocket science and it makes a huge difference. Every application developer should have this book and read it.
« Previous | 1 2 3 | Next »