Off the Top: Information Aggregation Entries
Showing posts: 91-105 of 136 total posts
Personal InfoCloud at WebVisions 2005
I, Thomas Vander Wal, will be presenting the Personal InfoCloud at the WebVisions 2005 in Portland, Oregon on July 15th. In all it looks to be a killer conference, just as it has been in the past. This year's focus is convergence (it is about time).
WebVisions is one of the best values in the web conference industry these days, as the early bird pricing is just $85 (US). You don't need an excuse, you just go. You spend a Friday bettering yourself and then Saturday in Powell's Books the evenings are spent talking the talk over some of the world's best beers served up fresh.
Explaining and Showing Broad and Narrow Folksonomies
I have been explaining the broad and narrow folksonomy in e-mail and in comments on others sites, as well as in the media (Wired News). There has still been some confusion, which is very understandable as it is a different concept that goes beyond a simple understanding of tagging. I have put together a couple graphics that should help provide a means to make this distinction some what clearer. The folksonomy is a means for people to tag objects (web pages, photos, videos, podcasts, etc., essentially anything that is internet addressable) using their own vocabulary so that it is easy for them to refind that information again. The folksonomy is most often also social so that others that use the same vocabulary will be able to find the object as well. It is important to note that folksonomies work best when the tags used to describe objects are in the common vocabulary and not what a person perceives others will call it (the tool works like no other for personal information management of information on the web, but is also shared with the world to help others find the information).
Broad Folksonomy
Let's begin with the broad folksonomy, as a tool like del.icio.us delivers. The broad folksonomy has many people tagging the same object and every person can tag the object with their own tags in their own vocabulary. This lends itself very easy to applying the power law curve (power curve) and/or net effect to the results of many people tagging. The power terms and the long tail both work.
The broad folksonomy is illustrated as follows. 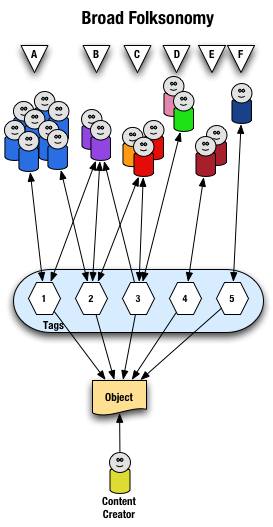
From a high level we see a person creates the object (content) and makes it accessible to others. Other people (groups of people with the same vocabulary represented people blobs and noted with alphabet letters) tag the object (lines with arrows pointing away from the people) with their own terms (represented by numbers). The people also find the information (arrows on lines pointing from the numeric tags back to the people blobs) based on the tags.
Digging a little deeper we see quite a few people (8 people) in group "A" and they have tagged the object with a "1" and a "2" and they use this term to find the object again. Group "B" (2 people) have applied tag "1" and "2" to the object and they use tag terms "1", "2", and "3" to find the information. Group "C" (3 people) have tagged the object with "2" and "3" so that they can find the object. Group "D" has also tagged the object with tag "3" so that they may refind the information this group may have benefitted from the tagging that group "C" provided to help them find the information in the first place. Group "E" (2 people) uses a different term, "4", to tag the object than others before it and uses only this term to find the object. Lastly, group "F" (1 person) uses tag "5" on the object so that they may find it.
Broad Folksonomy and the Power Curve
The broad folksonomy provides a means to see trends in how a broad range are tagging one object. This is an opportunity to see the power law curve at work and show the long-tail.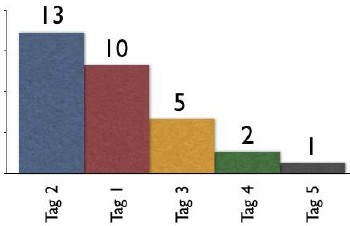
The tags spike with tag "2" getting the largest portion of the tags with 13 entries and tag "1" receiving 10 identical tags. From this point the trends for popular tags are easy to see with the spikes on the left that there are some trends, based on only those that have tagged this object, that could be used extract a controlled vocabulary or at least know what to call the object to have a broad spectrum of people (similar to those that tagged the object, and keep in mind those that tag may not be representative of the whole). We also see those tags out at the right end of the curve, known as the long tail. This is where there is a small minority of people who call the object by a term, but those people tagging this object would allow others with a similar vocabulary mindset to find the object, even if they do not use the terms used by the masses over at the left end of the curve. If we take this example and spread it out over 400 or 1,000 people tagging the same object we will se a similar distribution with even more pronounced spikes and drop-off and a longer tail.
This long tail and power curve are benefits of the broad folksonomy. As we will see the narrow folksonomy does not have the same properties, but it will have benefits. These benefits are non-existent for those just simply tagging items, most often done by the content creator for their own content, as is the means Technorati has done, even with their following tag links to destinations other than Technorati (as they initially had laid out). The benefits of the long tail and power curve come from the richness provided by many people openly tagging the same object.
Narrow Folksonomy
The narrow folksonomy, which a tool like Flickr represents, provides benefit in tagging objects that are not easily searchable or have no other means of using text to describe or find the object. The narrow folksonomy is done by one or a few people providing tags that the person uses to get back to that information. The tags, unlike in the broad folksonomy, are singular in nature (only one tag with the term is used as compared to 13 people in the broad folksonomy using the same tag). Often in the narrow folksonomy the person creating the object is providing one or more of the tags to get things started. The goals and uses of the narrow folksonomy are different than the broad, but still very helpful as more than one person can describe the one object. In the narrow the tags are directly associated with the object. Also with the narrow there is little way of really knowing how the tags are consumed or what portion of the people using the object would call it what, therefore it is not quite as helpful as finding emerging vocabulary or emergent descriptions. We do find that tags used to describe are also used for grouping, which is particularly visible and relevant in Flickr (this is also done in broad folksonomies, but currently not to the degree of visibility that it is done on Flickr, which may be part of the killer interactive environment Ludicorp has created for Flickr).
The narrow folksonomy is illustrated as follows.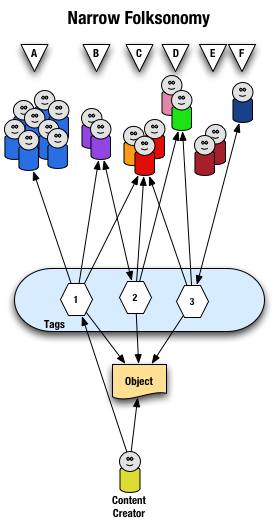
From a high level we see a person creates the object and applies a tag ("1") that represents what they call the object or believe describes the object. There are fewer tags provided than in a broad folksonomy and there is only one of each tag applied to the object. The consumers of the object also can apply tags that help them find the object or describe what they believe are the terms used to describe this object.
A closer look at the interaction between people and the object and tags in a narrow folksonomy shows us that group "A" uses tag "1" to find and come back to the object (did the creator do this on purpose? or did she just tag it with what was helpful to her). We see group "B" also using tag "1" to find the object, but they have tagged the object with tag "2" to also use as a means to find the object. Group "C" uses tag "1","2", and "3" to find the object and we also note this group did not apply any of its own tags to the object as so is only a consumer of the existing folksonomy. We see group "D" uses tags "2" and "3" to find the objects and it too does not add any tags. Group "E" is not able to find the object by using tags as the vocabulary it is using does not match any of the tags currently provided. Lastly, group "F" has their own tag for the object that they alone use to get back to the object. Group "F" did not find the object through existing tags, but may have found the object through other means, like a friend e-mailed them a link or the object was included in a group they subscribe to in their feed aggregator.
We see that the richness of the broad folksonomy is not quite there in a narrow folksonomy, but the folksonomy does add quite a bit of value. The value, as in the case of Flickr, is in text tags being applied to objects that were not findable using search or other text related tools that comprise much of how we find things on the internet today. The narrow folksonomy does provide various audiences the means to add tags in their own vocabulary that will help them and those like them to find the objects at a later time. We are much better off with folksonomies than we were with out them, even if it is a narrow folksonomy being used.
Conclusion
We benefit from folksonomies as the both the personal vocabulary and the social aspects help people to find and retain a tether to objects on the web that are an interest to them. Who is doing the tagging is important to understand and how the tags are consumed is an important factor. This also helps us see that not all tagging is a folksonomy, but is just tagging. Tagging in and of its self is a helpful step up from no tagging, but is no where near as beneficial as opening the tagging to all. Folksonomy tagging can provide connections across cultures and disciplines (an knowledge management consultant can find valuable information from an information architect because one object is tagged by both communities using their own differing terms of practice). Folksonomy tagging also makes up for missing terms in a site's own categorization system/taxonomy. This hopefully has made things a little clearer for all in our understanding the types of folksonomies and tagging and the benefits that can be derived.
This entry first appeared at Personal InfoCloud and comments are open for your use there.
Flickr and the Future of the Internet
Peter's post on Flickr Wondering triggers some thoughts that have been gelling for a while, not only about what is good about Flickr, but what is missing on the internet as we try to move forward to mobile use, building for the Personal InfoCloud (allowing the user to better keep information the like attracted to them and find related information), and embracing Ubicomp. What follows is my response to Peter's posting, which I posted here so I could keep better track of it. E-mail feedback is welcome. Enjoy...
You seemed to have hit on the right blend of ideas to bring together. It is Lane's picture component and it is Nadav's integration of play. Flickr is a wonderfully written interactive tool that adds to photo managing and photo sharing in ways that are very easy and seemingly intuitive. The navigations is wonderful (although there are a few tweak that could put it over the top) and the integration of presentational elements (HTML and Flash) is probably the best on the web as they really seem to be the first to understand how to use which tools for what each does best. This leads to an interface that seems quick and responsive and works wonderfully in the hands of many. It does not function perfectly across platforms, yet, but using the open API it is completely possible that it can and will be done in short order. Imagine pulling your favorites or your own gallery onto your mobile device to show to others or just entertain yourself.
Flickr not only has done this phenomenally well, but may have tipped the scales in a couple of areas that are important for the web to move forward. One area is an easy tool to extract a person's vocabulary for what they call things. The other is a social network that makes sense.
First, the easy tool for people to add metadata in their own vocabulary for objects. One of the hinderances of digital environments is the lack of tools to find objects that do not contain words the people seeking them need to make the connection to that object they are desiring. Photos, movies, and audio files have no or limited inherent properties for text searching nor associated metadata. Flickr provides a tool that does this easily, but more importantly shows the importance of the addition of metadata as part of the benefit of the product, which seems to provide incentive to add metadata. Flickr is not the first to go down this path, but it does it in a manner that is light years ahead of nearly all that came before it. The only tools that have come close is HTML and Hyperlinks pointing to these objects, which is not as easy nor intuitive for normal folks as is Flickr. The web moving forward needs to leverage metadata tools that add text addressable means of finding objects.
Second, is the social network. This is a secondary draw to Flickr for many, but it is one that really seems to keep people coming back. It has a high level of attraction for people. Part of this is Flickr actually has a stated reason for being (web-based photo sharing and photo organizing tool), which few of the other social network tools really have (other than Amazon's shared Wish Lists and Linkedin). Flickr has modern life need solved with the ability to store, manage, access, and selectively share ones digital assets (there are many life needs and very few products aim to provide a solution for these life needs or aims to provide such ease of use). The social network component is extremely valuable. I am not sure that Flickr is the best, nor are they the first, but they have made it an easy added value.
Why is social network important? Helping to reduct the coming stench of information that is resultant of the over abundance of information in our digital flow. Sifting through the voluminous seas of bytes needs tools that provide some sorting using predictive methods. Amazon's ratings and that matching to other's similar patterns as well as those we claim as our friends, family, mentors, etc. will be very important in helping tools predict which information gets our initial attention.
As physical space gets annotated with digital layers we will need some means of quickly sorting through the pile of bytes at the location to get a handful that we can skim through. What better tool than one that leverages our social networks. These networks much get much better than they are currently, possibly using broader categories or tags for our personal relationships as well as means of better ranking extended relationships of others as with some people we consider friends we do not have to go far in their group of friends before we run into those who we really do not want to consider relevant in our life structures.
Flickr is showing itself to be a popular tool that has the right elements in place and the right elements done well (or at least well enough) to begin to show the way through the next steps of the web. Flickr is well designed on many levels and hopefully will not only reap the rewards, but also provide inspiration to guide more web-based tools to start getting things right.
Would We Create Hierarchies in a Computing Age?
Lou has posted my question:
Is hierarchy a means to classify and structure based on the tools available at the time (our minds)? Would we have structured things differently if we had computers from the beginning?
Hierarchy is a relatively easy means of classifying information, but only if people are familiar with the culture and topic of the item. We know there are problems with hierarchy and classification across disciplines and cultures and we know that items have many more attributes that which provide a means of classification. Think classification of animals, is it fish, mammal, reptile, etc.? It is a dolphin. Well what type of dolphin, as there are some that are mammal and some that are fish? Knowing that the dolphin swims in water does not help the matter at all in this case. It all depends on the context and the purpose.
Hierarchy and classification work well in limited domains. In the wild things are more difficult. On the web when we are building a site we often try to set hierarchies based on the intended or expected users of the information. But the web is open to anybody and outside the site anybody can link to any thing they wish that is on the web and addressable. The naming for the hyperlink can be whatever helps the person creating the link understand what that link is pointing to. This is the initial folksonomy, hyperlinks. Google was smart in using the link names in their algorithm for helping people find information they are seeking. Yes, people can disrupt the system with Googlebombing, but the it just takes a slightly smarter tool to get around these problems.
You see hierarchies are simple means of structuring information, but the world is not as neat nor simple. Things are far more complex and each person has their own derived means of structuring information in their memory that works for them. Some have been enculturated with scientific naming conventions, while others have not.
I have spent the last few years watching users of a site not understand some of the hierarchies developed as there are more than the one or two user-types that have found use in the information being provided. They can get to the information from search, but are lost in the hierarchies as the structure is foreign to them.
It is from this context that I asked the question. We are seeing new tools that allow for regular people to tag information objects with terms that these people would use to describe the object. We see tools that can help make sense of these tags in a manner that gets other people to information that is helpful to them. These folksonomy tools, like Flickr, del.icio.us, and Google (search and Gmail) provide the means to tame the whole in a manner that is addressable across cultures (including nationalities and language) and disciplines. This breadth is not easily achievable by hierarchies.
So looking back, would we build hierarchies given today's tools? Knowing the world is very complex and diverse do simple hierarchies make sense?
Removing the Stench from Mobile Information
Standing in Amsterdam in front of the Dam, I was taking in the remnants of a memorial to Theodore van Gogh (including poetry to Theo). While absorbing what was in front of me, I had a couple people ask me what the flowers and sayings were about. I roughly explained the street murder of Theo van Gogh.
While I was at the Design Engaged conference listening to presentations about mobile information and location-based information I thought a lot about the moment at the Dam. I thought about adding information to the Dam in an electronic means. If one were standing at the Dam you could get a history of the Dam placed by the City of Amsterdam or a historical society. You could get a timeline of memorials and major events at the Dam. You could also get every human annotation.
Would we want every annotation? That question kept running reoccurring and still does. How would one dig through all the digital markings? The scent of information could become the "stench of information" very quickly. Would all messages even be friendly, would they contain viruses? Locations would need their own Google search to find the relevant pieces of information. This would all be done on a mobile phone, those lovely creatures with their still developing processors.
As we move to a world where we can access information by location and in some cases access the information by short range radio signals or touching our devices there needs to be an easy to accept these messages. The messaging needs some predictive understanding on our mobiles or some preparsing of content and messaging done remotely (more on remote access farther down).
If was are going to have some patterning tools built in our mobiles what information would they need to base predictions? It seems the pieces that could make it work are based on trust, value, context, where, time, action, and message pattern. Some of this predictive nature will need some processing power on the mobile or a connection to a service that can provide the muscle to predict based on the following metadata assets of the message.
Trust is based on who left the message and whether you know this person or not. If the person is known do you trust them? This could need an ensured name identification, which could be mobile number, their tagging name crossed with some sort of key that proves the identity, or some combination of known and secure metadata items. It would also be good to have a means to identify the contributor as the (or an) official maintainer of the location (a museum curator annotating galleries in a large museum is one instance). Some trusted social tool could do some predicting of the person's worthiness to us also. The social tools would have to be better than most of today's variants of social networking tools as they do not have the capability for us to have a close friend, but not really like or trust their circle(s) of friends. It would be a good first pass to go through our own list of trusted people and accept a message left by any one of these people. Based on our liking or disliking of the message a rating would be associated with this person to be used over time.
Value is a measure of the worthiness of the information, normally based on the source of the message. Should the person who left the message have a high ranking of content value it could be predicted that the message before us is of high value. If these are message that have been reviews of restaurants and we have liked RacerX previous reviews we found in five other cities and they just gave the restaurant we are in front of a solid review that meets our interests. Does RacerX have all the same interests?
Context is a difficult predictive pattern as there are many contextual elements such as mood, weather, what the information relates to (restaurant reviews, movie reviews, tour recommendations, etc.). Can we set our mood and the weather when predicting our interest in a message. Is our mood always the same in certain locations?
Where we are is more important than location. Yes, do we know where we are? Are we lost? Are we comfortable where we are? These are important questions that may help be a predictor that are somewhat based on our location. Or location is the physical space we occupy, but how we feel about that spot or what is around us at that spot may trigger our desire to not accept a location-based message. Some of us feel very comfortable and grounded in any Chinatown anywhere around the globe and we seek them out in any new city. Knowing that we are in or bordering on a red-light district may trigger a predictive nature that would turn off all location-based messages. Again these are all personal to us and our preferences. Do our preferences stay constant over time?
Time has two variables on two planes. The first plane is our own time variables while the other relates to the time of the messages. One variable is the current moment and the other is historical time series. The current moment may be important to us if it is early morning and we enjoy exploring in the early morning and want to receive information that will augment our explorative nature. Current messages may be more important than historical messages to us. The other variable of historical time and how we treat the past. Some of us want all of our information to be of equal value, while others will want the most current decisions to have a stronger weight so that new events can keep information flowing that is most attune to our current interests and desires. We may have received a virus from one of our recent messages and want to change our patterns of acceptance to reflect our new cautionary nature. We may want to limit how far back we want to read messages.
Action is a very important variable to follow when the possibility of malicious code can damage our mobile or the information we have stored in the mobile or associated with that mobile. Is the item we are about to receive trigger some action on our device or is is a static docile message. Do we want to load active messages into a sandbox on our mobile so the could not infect anything else? Or, do we want to accept the active messages if they meet certain other criteria.
Lastly, message pattern involved the actual content of the message and would predict if we would want to read the information if it is identical or similar to other messages, think attention.xml. If the Dam has 350 messages similar to "I am standing at the Dam" I think we may want to limit that to ones that meet some other criteria or to just one, if we had the option. Do we have predictors that are based on the language patterns in messages? Does our circle of trusted message writers always have the same spellings for certain wordz?
All of these variables could lead to a tight predictive pattern that eases the information that we access. The big question is how is all of this built into a predictive system that works for us the moment we get our mobile device and start using the predictive services? Do we have a questionnaire we fill out that creates our initial settings? Will new phones have ranking buttons for messages and calls (nice to rank calls we received so that our mobile would put certain calls directly into voice mail) so it is an easier interface to set our preferences and patterns.
Getting back to remote access to location-based information seems, for me, to provide some excellent benefits. There are two benefits I see related to setting our predictive patterns. The first is remote access to information could be done through a more interactive device than our mobile. Reading and ranking information from a desktop on a network or a laptop on WiFi could allow us to get through more information more quickly. The second benefit is helping us plan and learn from the location-based information prior to our going to that location so we could absorb the surroundings, like a museum or important architecture, with minimal local interaction with the information. Just think if we could have had our predictive service parse through 350 messages that are located at the Dam and we previews the messages remotely and flagged four that could have interest to us while we are standing at the Dam. That could be the sweet smell of information.
That Syncing Feeling (text)
My presentation of That Syncing Feeling is available. Currently the text format is available, but a PDF will be available at some point in the future (when more bandwidth is available). This was delivered at Design Engaged in Amsterdam this morning. More to follow...
That Synching Feeling in Amsterdam
No I am not in hiding, I am popping up on some favorite lists and comment sections of sites. I am spending my free time working on a presentation for Design Engaged entitled "That Syncing Feeling". The focus of the 15 minutes presentation (yes, this is hell for me) is the future of keeping your information with you, particularly when you need it. Yes, this is an essential part of the Personal InfoCloud, which still requires a manual process today. I will hopefully show how close we are and what metadata will be needed to help us accomplish this feat.
If you are not one of the 25 folks in Amsterdam for this session I will post the presentation, perhaps even an annotated version if you are good like you always are.
Web 2.0: Source, Container, Presentation
At Web 2.0 Jeff Bezos, of Amazon stated, "Web 2.0 is different. It's about AWS (Amazon Web Services). It's not on the web site for users to see. It's about making the internet useful for computers.". This is very appropriate today as it breaks the information model into at least three pieces: source, container, and presentation. Web 1.0 often had these three elements in one place, which really made it difficult to reuse the information, but even use it at times.
The source is the raw information or content from the creator or main distributor. The container is the means of transporting the information or content. The container can be XML, CSV, text, XHTML, etc. The presentation is what is used to make the information or content human consumable. The presentation can be HTML with CSS, Flash, PDF, feed reader, mobile application, desktop application, etc.
The importance of the three components is they most valuable when they stand alone. Many problems and frustrations for people trying to get information and reuse it off the web has been there has not been a separation of the components. Take most Flash files, which tie the container and the presentation in one object that is proprietary and can be extremely difficult to extract the information for reuse. The same also applies to PDF files as they too are less than optimal for sharing information for anything other than reading, if the PDF can be read on the device. As mobile use of the internet increases the separation is much more valuable. The separation has always been the smart thing to do.
Today Google launched a beta of their Google SMS for mobile devices. The service takes advantage of the Google web services (source) and allows mobile users to send a text message with a query (asking "pizza" and providing the zip code) and Google responds with a text message with information (local pizzerias with their address and phone numbers). The other day Tantek demonstrated Semantic XHTML as an API, which provides openly accessible information that is aggregated and reused with a new presentation layer, Flash.
More will follow on this topic at some point in the not too distant future, once I get sleep.
Personal Information Aggregation Nodes
Agnostic aggregators are the focal point of information aggregation. The tools that are growing increasingly popular for the information aggregation from internet sources are those that permit the incorportation of info from any valid source. The person in control of the aggregator is the one who chooses what she wants to draw in to their aggregator.
People desiring info agregation seemingly want to have control over all sources of info. She wants one place, a central resource node, to follow and to use as a starting point.
The syndication/pull model not only adds value to the central node for the user, but to those points that provide information. This personal node is similar (but conversely) to network nodes in that the node is gaining value as the individual users make use of the node. The central info aggregation node gains value for the individual the more information is centralized there. (The network nodes gain value the more people use them, e.g. the more people that use del.icio.us the more valuable the resource is for finding information.) This personal aggregation become a usable component of the person's Personal InfoCloud.
What drives the usefulness? Portability of information is the driver behind usefulness and value. The originating information source enables value by making the information usable and reusable by syndicating the info. Portabiliry is also important for the aggregators so that information can move easily between devices and formats.
Looking a del.icio.us we see an aggrgator that leverages a social network of people as aggregators and filters. Del.icio.us allows the user to build their own bookmarks that also provides a RSS feed for those bookmarks (actually most everything in del.icio.us provides feeds for most everything) and an API to access the feeds and use then as the user wishes. This even applies to using the feed in another aggregator.
The world of syndication leads to redundant information. This where developments like attention.xml will be extremely important. Attention.xml will parse out redundant info so that you only have one resource. This work could also help provide an Amazon like recommendation system for feeds and information.
The personal aggregation node also provides the user the means to categorize information as they wish and as makes most sense to themselves. Information is often not found and lost because it is not categorized in a way that is meaningful to the person seeking the information (either for the first time or to access the information again). A tool like del.icio.us, as well as Flickr, allows the individual person to add tags (metadata) that allows them to find the information again, hopefully easily. The tool also allows the multiple tagging of information. Information (be it text, photo, audio file, etc.) does not always permit itself easy narrow classification. Pushing a person to use distinct classifications can be problematic. On this site I built my category tool to provide broad structure rather than heirarchial, because it allows for more flexibility and can provide hooks to get back to information that is tangential or a minor topic in a larger piece. For me this works well and it seems the folksonomy systems in del.icio.us and Flickr are finding similar acceptance.
Feed On This
The "My" portal hype died for all but a few central "MyX" portals, like my.yahoo. Two to three years ago "My" was hot and everybody and their brother spent a ton of money building a personal portal to their site. Many newspapers had their own news portals, such as the my.washingtonpost.com and others. Building this personalization was expensive and there were very few takers. Companies fell down this same rabbit hole offering a personalized view to their sites and so some degree this made sense and to a for a few companies this works well for their paying customers. Many large organizations have moved in this direction with their corporate intranets, which does work rather well.
Where Do Personalization Portals Work Well
The places where personalization works points where information aggregation makes sense. The my.yahoo's work because it is the one place for a person to do their one-stop information aggregation. People that use personalized portals often have one for work and one for Personal life. People using personalized portals are used because they provide one place to look for information they need.
The corporate Intranet one place having one centralized portal works well. These interfaces to a centralized resource that has information each of the people wants according to their needs and desires can be found to be very helpful. Having more than one portal often leads to quick failure as their is no centralized point that is easy to work from to get to what is desired. The user uses these tools as part of their Personal InfoCloud, which has information aggregated as they need it and it is categorized and labeled in a manner that is easiest for them to understand (some organizations use portals as a means of enculturation the users to the common vocabulary that is desired for use in the organization - this top-down approach can work over time, but also leads to users not finding what they need). People in organizations often want information about the organization's changes, employee information, calendars, discussion areas, etc. to be easily found.
Think of personalized portals as very large umbrellas. If you can think of logical umbrellas above your organization then you probably are in the wrong place to build a personalized portal and your time and effort will be far better spent providing information in a format that can be easily used in a portal or information aggregator. Sites like the Washington Post's personalized portal did not last because of the cost's to keep the software running and the relatively small group of users that wanted or used that service. Was the Post wrong to move in this direction? No, not at the time, but now that there is an abundance of lesson's learned in this area it would be extremely foolish to move in this direction.
You ask about Amazon? Amazon does an incredible job at providing personalization, but like your local stores that is part of their customer service. In San Francisco I used to frequent a video store near my house on Arguello. I loved that neighborhood video store because the owner knew me and my preferences and off the top of his head he remembered what I had rented and what would be a great suggestion for me. The store was still set up for me to use just like it was for those that were not regulars, but he provided a wonderful service for me, which kept me from going to the large chains that recorded everything about me, but offered no service that helped me enjoy their offerings. Amazon does a similar thing and it does it behind the scenes as part of what it does.
How does Amazon differ from a personalized portal? Aggregation of the information. A personalized portal aggregates what you want and that is its main purpose. Amazon allows its information to be aggregated using its API. Amazon's goal is to help you buy from them. A personalized portal has as its goal to provide one-stop information access. Yes, my.yahoo does have advertising, but its goal is to aggregate information in an interface helps the users find out the information they want easily.
Should government agencies provide personalized portals? It makes the most sense to provide this at the government-wide level. Similar to First.gov a portal that allows tracking of government info would be very helpful. Why not the agency level? Cost and effort! If you believe in government running efficiently it makes sense to centralize a service such as a personalized portal. The U.S. Federal Government has very strong restriction on privacy, which greatly limits the login for a personalized service. The U.S. Government's e-gov initiatives could be other places to provide these services as their is information aggregation at these points also. The downside is having many login names and password to remember to get to the various aggregation points, which is one of the large downfalls of the MyX players of the past few years.
What Should We Provide
The best solution for many is to provide information that can be aggregated. The centralized personalized portals have been moving toward allowing the inclusion of any syndicated information feed. Yahoo has been moving in this direction for some time and in its new beta version of my.yahoo that was released in the past week it allows the users to select the feeds they would like in their portal, even from non-Yahoo resources. In the new my.yahoo any information that has a feed can be pulled into that information aggregator. Many of us have been doing this for some time with RSS Feeds and it has greatly changed the way we consume information, but making information consumption fore efficient.
There are at least three layers in this syndication model. The first is the information syndication layer, where information (or its abstraction and related metadata) are put into a feed. These feeds can then be aggregated with other feeds (similar to what del.icio.us provides (del.icio.us also provides a social software and sharing tool that can be helpful to share out personal tagged information and aggregations based on this bottom-up categorization (folksonomy). The next layer is the information aggregator or personalized portals, which is where people consume the information and choose whether they want to follow the links in the syndication to get more information.
There is little need to provide another personalized portal, but there is great need for information syndication. Just as people have learned with internet search, the information has to be structured properly. The model of information consumption relies on the information being found. Today information is often found through search and information aggregators and these trends seem to be the foundation of information use of tomorrow.
43folders for Refining Your Personal InfoCloud
I have been completely enjoying Merlin Mann's 43folders the past couple weeks. It has been one of my guilty pleasures and great finds. Merlin provides insights to geeks (some bits are Mac oriented) on how to better organize the digital information around them (or you - if the shoe fits). This is a great tutorial on refining your Personal InfoCloud, if I ever saw one.
Everytime I read this I do keep thinking about how Ben Hammersley has hit it on the head with the Two Emerging Classes. The volume of information available, along with the junk, and the skills needed to best find and manage the information are not for the technically meek.
Fixing Permalink to Mean Something
This has been a very busy week and this weekend it continues with the same. But, I took two minutes to see if I could solve a tiny problem bugging me. I get links to the main blog, Off the Top, from outside search engines and aggregators (Technorati, etc.) that are referencing content in specific entries, but not all of those entries live on the ever-changing blog home page. All of the entries had the same link to their permanant location. The dumb thing was every link to their permanant home was named the same damn thing, "permalink". Google and other search engines use the information in the link name to give value to the page being linked to. Did I help the cause? No.
So now every permanent link states "permalink for: incert entry title". I am hoping this will help solve the problem. I will modify the other pages most likely next week sometime (it is only a two minute fix) as I am toast.
Back and Digging Out
Coming back from six plus days of being untethered from the net I found I had 1117 unread RSS feeds. This is worse than my personal e-mail stack, which was just over 550 (I get to my work e-mail stack tomorrow, which averages about 80 e-mails per day). The RSS feeds really threw me as I was not expecting it to have snowballed like that.
There were a few things I was wanting to follow that I knew may pop their heads up while I was away so I followed these on my Treo 600 on Google News and del.icio.us aggregator. I was able to find most of what I was looking for and do a quick read and then e-mail an annotated link to one of my personal e-mail accounts. I did find some things on del.icio.us that I just copied into my del.icio.us bookmarks so I could come back to them later.
I got far less done on the writing front as my son was along for the vacation, which made it a real family vacation and not the usual working vacation with the laptop on my lap on the front porch when I am not playing in the waves. No, I would not say I am rested, but I do have more wonderful memories of a great summer get away. Our time schedules shifted to a 10 month-old's eating and sleeping schedule. When we drifted to our normal shore vacation schedule we had a cranky kid, which only took two days to convert to a vacation fully focused on the kid. We met many wonderful new people, stayed in a different B&B, and found a new restaurant to add to our favorites.
I am now ready for the last two days of the week and to start responding to e-mail tomorrow. I am also ready to tackle my writing assignments that are well over due. My laptop is also fully updated with OS and software updates that make it really sing, too bad Windows updates never make the machine perceivably faster.
Now Delicious
Time has been very thin of late. In the past six months or so started noticing an increasing number of links from del.icio.us and started pulling the feeds of some folks I like to follow their reading list into my site feed aggregator. I had about four or five del.icio.us feeds in my aggregator (meta aggregation of other's meta aggregations - MetaAg MetaAg). This past week I was taking medicine that tweaked by sleep patterns so I had some free awake time after midnight and I finally set up my own vanderwal del.icio.us feed.
I like having the ability to pull [meta] tags aggregations that others have used, like security, which is a great help during the day at work. I can also track some topics I keep finding myself at the periphery and ever more interested in as they tie to some personal projects.
I did consider something similar with Feedster, but it was down for updating recently when I had the tiny bit of time to fiddle with setting something up. By the way, Feedster is now Standards-based (not fully valid, but rather close) and it loads very quickly (most of the time).
Tantek Mulls Contact Info Updating
Tantek mulls a means to keep contact info upto date. This should be much easier than Tantek has made out. This could be as easy as publishing one's own vcard that is pointed to with RSS. When the vcard changes the RSS feed notifies the contact info repositories and they grab the vcard and update the repository's content. This is essentially pulling content information into the user's Personal InfoCloud. (Contact info updating and applications are a favorite subject of mine to mull over.)
Why vcard? It is a standard sharing structure that all contact information applications (repositories understand). Most of us have more than one contact repository: Outlook at work; Lotus Organizer on the workstation at home; Apple Address Book and Entourage on the laptop; Palm on the Cellphone PDA; and Addresses in iPod. All of these applications should synch and perfectly update each other (deleting and updating when needed), but they do not. Keeping vcard field names and order constant should permit the info to have corrective properties. The vCard RDF W3C specifications seem to layout existing standards that should be adopted for a centralized endeavor.
What not Plaxo? Plaxo is limited to applications I do not run everywhere (for their download version) and its Web version is impractical as when I need contact information I am most often not in front of a terminal, I am using a Treo or pulling the information out of my iPod.
While Tantek's solution is good and somewhat usable it is not universal as a vCard RDF would be with an application that pinged the XML file to check for an update daily or every few days.